Introduction Diverse imaging modalities exist for evaluation of stroke. Since its first application in brain Magnetic Resonance Imaging (MRI), diffusion weighted imaging (DWI) became one of the essential and optimal techniques for diagnosing acute ischemic stroke1,2. DWI exhibits tissue characteristics by providing information of the random motion of the water molecules, so-called Brownian movement in
Addressing fairness issues in deep learning-based medical image analysis: a systematic review
Abstract
Deep learning algorithms have demonstrated remarkable efficacy in various medical image analysis (MedIA) applications. However, recent research highlights a performance disparity in these algorithms when applied to specific subgroups, such as exhibiting poorer predictive performance in elderly females. Addressing this fairness issue has become a collaborative effort involving AI scientists and clinicians seeking to understand its origins and develop solutions for mitigation within MedIA. In this survey, we thoroughly examine the current advancements in addressing fairness issues in MedIA, focusing on methodological approaches. We introduce the basics of group fairness and subsequently categorize studies on fair MedIA into fairness evaluation and unfairness mitigation. Detailed methods employed in these studies are presented too. Our survey concludes with a discussion of existing challenges and opportunities in establishing a fair MedIA and healthcare system. By offering this comprehensive review, we aim to foster a shared understanding of fairness among AI researchers and clinicians, enhance the development of unfairness mitigation methods, and contribute to the creation of an equitable MedIA society.
Introduction
The progressive advancement of artificial intelligence (AI) has garnered substantial attention and development in recent years, showcasing its efficacy in diverse practical applications such as autonomous driving, recommendation systems, and more. Notably, the data-centric approach inherent in AI methodologies has emerged as an indispensable asset in the domains of healthcare and medical image analysis.
Amidst the substantial research dedicated to refining the performance of machine learning (ML) or deep learning (DL) algorithms, a notable concern has surfaced among researchers. Although the performance of DL models may vary due to algorithmic factors such as random seed, some researchers witness a consistent performance fluctuation among patients with diverse characteristics or what is referred to as sensitive attributes. For instance, Stanley et al.1 evaluated the disparities in performance and saliency maps in sex prediction using MR images, observing considerable discrepancies between White and Black children. Similarly, CheXclusion found that female, Black, and low socioeconomic status patients were more likely to be under-diagnosed, as compared to their male, White, and high socioeconomic status counterparts in chest X-ray datasets2. This situation is not unique in medical image analysis (MedIA). Plenty of studies have addressed the existence of unfairness across multiple imaging modalities (MRI3,4, X-ray2,5,6) and body parts (brain7,8,9, chest10, heart3,4, skin11,12), and different sensitive attributes (sex9,13, age14,15, race16,17, skin tone18,19). Besides, this issue is also found in other healthcare applications where the inputs to the system are electronic medical records20,21 or RNA sequences22.
The phenomenon where the effectiveness of DL models notably favors or opposes one subgroup over another is termed unfairness23. This issue is of profound ethical significance and necessitates urgent attention, as it contravenes fundamental bioethical principles24. Moreover, it poses substantial impediments to developing reliable and trustworthy DL systems for clinical applications25. One thing that must be taken in mind is that current studies about fairness mainly focus on the mathematical notions of fairness, i.e., using pre-defined metrics to measure the degree of unfairness. However, this form of definition does have shortcomings, as it can only deal with correlations rather than causation, leading to challenges in understanding how fairness statistics are derived and attributing responsibility26. Besides, as the societal definitions of fairness evolve and are perceived differently by individuals, it is hard to find a proper formula to describe fairness consistently27.
Failure to adequately address fairness issues could result in a subgroup of patients receiving inaccurate or under-diagnoses2,28,29, potentially leading to deterioration and causing lifelong harm to the patients. Clinicians may face difficulties in placing trust and confidently integrating deep learning methods into their routine practices. Recently, several studies in medical areas have urged the assessment of fairness in MedIA, including surgery30, nuclear medicine31, and dental care32, which shed light on this area. Nonetheless, owing to distinct research focuses and various scopes in comprehending issues among AI scientists and clinicians, it is imperative to establish a bridge for understanding fairness between these two groups25.
To this end, we have undertaken a systematic review aimed at addressing fairness concerns within DL-based MedIA. This review endeavors to introduce fundamental fairness concepts while categorizing existing studies about fair MedIA. Our aspiration is that this comprehensive review will aid both AI scientists and clinicians in understanding the present landscape and necessities concerning fair MedIA, thereby fostering the advancement of fair medical AI.
Results
The basics of group fairness
Fairness, as a concept describing collective societal problems, has been discussed widely throughout the development of human society25. Although the definition of fairness varies in different areas, the gist is the same, i.e., all citizens should have the right to be treated equally and equitably. In AI research, fairness can be categorized into individual fairness33, group fairness34, max-min fairness35, counterfactual fairness36, etc. Among them, group fairness is used by most of the studies in DL-based MedIA. Thus, in this section, we present the basics of group fairness for better comprehension.
Group fairness requires that the DL model should have equal utilities for all the subgroups in the test set. Specifically, supposing a scenario where each subject in the dataset is a triplet, i.e., Si = {Xi, Yi, Ai}, where Xi denotes the image data of subject Si, Yi denotes the target label, and Ai denotes the protected sensitive attributes.
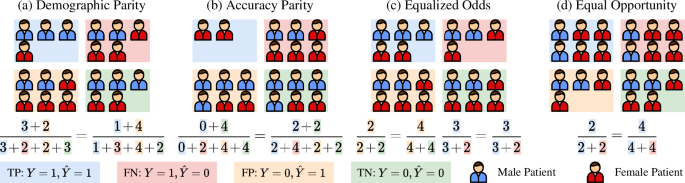
The general pipeline of group fairness evaluation is as follows. First, the test set is split into mutually exclusive subgroups by the sensitive attribute Ai. In MedIA, sensitive attributes can be information about the patients, including age, sex, race, skin tone, blood type, handedness, BMI, etc. Then, several group-wise fairness metrics are computed over each subgroup. The commonly used fairness criteria are shown in Table 1. For better understanding, we simulate four toy phenomenons where one of these fairness criteria is satisfied in Fig. 1. For example, as shown in Fig. 1a, ideal demographic parity requires the Male and Female groups to have equal probability of being predicted as illness, i.e. (P(hat{Y}=1| A=0)=P(hat{Y}=1| A=1)). However, these fairness indicators could contradict each other and might not be satisfied at the same time. For example, as shown in Fig. 1a, the demographic parity is achieved. However, the accuracy of the Male group, i.e., ({{rm{ACC}}}_{{rm{Male}}}=P(hat{Y}=Y| A=0)=frac{3+3}{3+2+2+3}=frac{3}{5}), while the accuracy of the Female group, i.e., ({{rm{ACC}}}_{{rm{Female}}}=P(hat{Y}=Y| A=1)=frac{1+2}{1+3+4+2}=frac{3}{10}), which means that the Accuracy Parity is not satisfied. Thus, it is important to select proper fairness criteria based on specific tasks37. Finally, the disparity between group-wise fairness metrics is computed to judge the overall fairness. The measurement function could be subtraction38, division38, SER3, STD39, NR19, etc.
Full size table

From left to right: a Demographic Parity, b Accuracy Parity, c Equalized Odds, d Equal Opportunity. The equations below compute the value of different criteria for the Male and Female groups.
Full size image
Compared to individual fairness33, which requires similar outputs for similar samples and is easy to be affected by the outlier samples, group fairness stabilizes the fairness analysis by group-wise average measurements. But also has shortcomings as the model might satisfy fairness constraints in one grouping scheme while being unfair in another group scheme, resulting in an ambiguous conclusion. For example, Fig. 2 shows a situation where the patients can be split into subgroups based on sex and race (White/Black). Although DP is satisfied on sex, i.e., (P(hat{Y}=1| A={rm{Male}})=frac{5}{10}=P(hat{Y}=1| A={rm{Female}})), DP is not satisfied with race, i.e., (P(hat{Y}=1| A={rm{White}})=frac{6}{10}ne frac{4}{9}=P(hat{Y}=1| A={rm{Black}})).

In a scenario involving two sensitive attributes, namely sex (male, female) and race (White, Black), demographic parity is achieved concerning sex but not race.
Full size image
A total of 687 papers were identified by our systematic research. After removing duplicates and irrelevant studies based on our criteria (see “Methods” section), 63 studies were included for information extraction and categorization. Figure 3 presents the flowchart of this review based on PRISMA. Figure 4 and Table 2 describe the statistics of the extracted data.

* denotes that six studies have been overcounted due to their involvement in research across multiple directions. FE fairness evaluation, UM unfairness mitigation, Pre pre-processing, In in-processing, Post post-processing.
Full size image

a Annual trends in research on fairness in MedIA. b Prevalence of various medical imaging modalities, research tasks, and associated sensitive attributes.
Full size image
Full size table
From Figs. 3 and 4, we can find that research about fairness in MedIA began in 2019 and the annual number of publications grew about 6–7 per year. Fairness in MedIA is mainly assessed on Brain MRI, Dermatology, and Chest X-ray. This is easy to understand as the development of the brain is highly related to sex and age, while the skin part usually appears in dermatology images, which may lead to spurious relations for diagnosis. Chest X-ray, however, has the largest amount of samples compared to other modalities, which provides a potential for evaluating fairness. Besides, most of the current research focuses on classification and segmentation. Some attempts have also been conducted on anomaly detection40 and regression12. As for the sensitive attributes, sex, age, race, and skin tone are the most concerned.
Specifically, the research about fairness in MedIA mainly consists of two folds. One aims at benchmarking fairness in various medical tasks and discovering the mechanism behind unfair performances, and the other category attempts to mitigate unfairness in current applications. The studies about fairness evaluation pay more attention to the existence of unfairness in various medical applications. While unfairness mitigation via in-processing strategies is more often considered (24/43). Note that some studies include research in multiple directions thus we repeat counts in Fig. 3.
Fairness evaluation
The starting point of addressing fairness issues in MedIA is to evaluate the existence of unfairness in MedIA tasks, by applying performance comparison among different sensitive groups. On the other hand, some researchers try to discover visual patterns that account for unfair model performance and study the relationship between fairness and other concepts.
Up to now, plenty of studies have been conducted on benchmarking unfairness in MedIA tasks. These studies evaluate diagnosis performance either on multiple network architectures or trained with different attribute ratios.
These studies vary in body parts and modalities, including brain MR1,7,41,42,43, breast MR44, Mammography45, Chest X-ray2,5,6, cardiac MR4, head and neck PET/CT46, and skin lesion47,48. Not surprisingly, most of the studies notice significant subgroup disparities in the utility except for the study in ref. 47, which does not find an observable trend between model utility and skin tone48. Recently, researchers expanded the range of tasks and the type of algorithms, such as regression49, anomaly detection40, reconstruction50, multi-instance learning51, random forest44, and transformer52, which fills the gap in fair MedIA. Besides, Zong et al.53 benchmark ten unfairness mitigation methods on nine medical datasets. However, they find that none of the ten methods outperforms the baseline with statistical significance. Similar results are also found in CXR-Fairness54.
To go further, some research examines whether the subgroup ratio in the train set affects the performance of DL models. Larrazaba et al.13 train DL models on Chest X-ray datasets and find that the diagnosis performance between the female and the male is significantly different. This phenomenon could result from the fact that the diagnosis for one subgroup is more difficult than that for another subgroup, due to different image quality55. Opposite to this finding, Petersen et al.9 evaluate the performance of DL models on the ADNI dataset with different subgroup ratios and notice that the performance of the under-represented group is not significantly different from that of the over-represented group. Besides, Ioannou et al.8 examine fairness by comparing the average Dice Similarity Coefficient (DSC) on each spatial location. Interestingly, they find that although unfairness exists in some regions severely, in other regions the DSC shows little or no disparity, which prompts us that unfairness evaluation should be conducted on different components respectively rather than on the overall utility.
Another category of studies focuses on unfairness source tracing and mechanism discovery. To discover the source of unfairness, many studies focus on the visual disparities among samples with different attributes, which are recognized widely across different modalities56, and suppose that unfairness comes from visual differences. For example, as shown in Fig. 5, there is a huge visual disparity between the White and the Black, the male and the female, and the young and the old. Liang et al. try to generate a sex-inverted X-ray image using a generative adversarial network and focus on the regions that have the largest disparity between the original image and its sex-inverted counterpart. By comparing the visual differences between the two images, they come up with some insights for understanding the source of unfairness and improving the DL models’ interpretability. Similarly, Jimenez-Sanchez et al.57 witness that the drain in the chest X-ray images may lead to shortcut learning for DL models, which causes unfairness. On the other hand, Jones et al.58 notice that the ability of classifiers to separate individuals into subgroups is highly relevant to subgroup disparity. Besides, Kalb et al.48 find that the level of unfairness varies when computing the Individual Typology Angle (ITA) of the image using different methods, which proves that unfairness comes from the label annotation procedure. In chest X-ray diagnosis, Weng et al.59 suppose that the differences in the imaging quality of the breasts between the male and the female are the reason for unfairness. Although the result does not support this hypothesis, their research gives insights for inspecting the source of unfairness. Moreover, Du et al.50 evaluate model fairness in MRI reconstruction tasks and find that the estimated Total Intracranial Volume and normalized Whole Brain Volume might be the cause of unfairness.

a, b images with dark skin and light skin from Fitzpatrick-17 Dataset162; c, d images of a male patient and a male patient from FairSeg Dataset169.
Full size image
Uncertainty also has a relationship with fairness. Lu et al.60 try to compare several uncertainty measurements by evaluating subgroup disparity and find that although the aggregate utilities are similar, subgroup disparity varies among different uncertainty measurements. However, the result of ref. 12 conducted on three clinical tasks shows that although some unfairness mitigation methods have positive effects on fairness, they might harm the uncertainty of the model prediction.
Unfairness mitigation
According to ref. 11, strategies aiming at unfairness mitigation can be categorized into pre-processing, in-processing, and post-processing. The schematic diagram of each category is shown in Fig. 6.

a Pre-processing methods. D1, D2: Two independent datasets; Dorigin, Dsynthesis: The original dataset and synthesized dataset. b In-processing methods. ({mathbb{FE}},{mathbb{TB}},{mathbb{SB}}): Feature Extractor, Target Branch, and Sensitive Branch, which are three parts of an adversarial network; f: latent feature vector; (y,a,hat{y},hat{a}): the ground truth target task label, sensitive attributes, and their corresponding predictions generated by the neural network; ({{mathcal{L}}}_{CE}): Cross-Entropy loss, measuring the difference between the predicted label and the ground truth label; ({{mathcal{L}}}_{{rm{Dis}}}): Disentanglement loss, for example, MMD-Loss170, measuring the distance between two distribution; ({D}_{00}^{10}): requiring the maximum distance between ({f}_{0}^{0}) and ({f}_{0}^{1}); ({d}_{00}^{01}): requiring the minimum distance between ({f}_{0}^{0}) and ({f}_{1}^{0}). c Post-processing methods. ({{mathbb{NN}}}^{* }): a pre-trained and fixed Neural Network; ylogits: predicted probability of y, range from 0 to 1; ({{mathbb{NN}}}^{p}): pruned ({mathbb{N{N}^{* }}}); Δ(ACC0, ACC1): difference between accuracy on subgroup test set Da=0 and Da=1.
Full size image
The pre-processing methods mainly focus on data modification or remedy, which can be categorized into data re-distribution, harmonization, aggregation, and synthesis.
Re-distribution addresses unfairness by adjusting the balance of subgroups. This can be achieved by either resampling the train set or by controlling the number of samples in different subgroups within each mini-batch. By ensuring a more balanced representation of subgroups, re-distribution can help to mitigate unfairness in DL models. Puyol-Antón et al.3 adopt stratified batch resampling on the baseline model and notice a significant improvement in fairness. This strategy is also proved to be efficient in ref. 61.
Data harmonization removes sensitive information from the input images. This can be conducted by using segments or bounding boxes to remove the skin part from dermatological images62,63, enhancing lesion boundary using image processing method64, applying Z-score normalization or ComBat algorithm65, or using differential privacy methods66. Recently, Yao et al.67 use a language-guided sketching model to transform the input images into sketches. Their result shows less disparity among subgroups, which indicates the potential of data harmonization in mitigating unfairness.
Data aggregation mitigates unfairness using information introduced by external datasets. The external dataset could be in the same modality5,68 or different modalities69. For example, Zhou et al.69 adopt the information of electronic health record data via an ElasticNet and improve the fairness of the model on pulmonary embolism detection by multi-modal fusion.
Data synthesis uses generative models to synthesize new samples to increase the number of training samples and balance the subgroup ratio in the training set. This can be done by either generating new samples with the same sensitive attribute as the original samples while varying in target label70 or by generating new samples with opposite sensitive attributes but preserving the target label19,71,72.
The in-processing methods focus on adjusting the architecture of models or adding extra losses or constraints to reduce biases among subgroups.
The adversarial architecture is the most common in-processing method, which adds an adversarial branch to the original architecture to minimize the influence of sensitive information in the latent space by using a gradient reversal layer as the adversarial branch3,15,21,73,74,75,76,77,78. The biggest difference between them is the choice of loss functions for sensitive attribute prediction, One step further, Li et al.18 add an extra branch except for the adversarial one, which predicts the degree of fairness on the test set without knowing the sensitive attributes.
Another category of in-processing methods directly adds fairness-related constraints to the optimization objective. The constraints include GroupDRO61, differentiable proxy functions of fairness metrics10,79, bias-balanced Softmax80, and margin ranking loss81. However, as shown in10, this type of method can lead to over-parametrization and overfitting, resulting in a fluid decision boundary that can lead to fairness gerrymandering82, i.e., the DL models might be fair on sex and age, respectively, but are unfair when evaluated on the combination of sex and age.
Disentanglement learning extracts the feature vector from the input image and projects the feature vector into a task-agnostic portion and a task-related portion. This can be achieved by either maximizing the entropy of the task-agnostic portion83 or by maximizing the orthogonality between the task-agnostic and the task-related portions17. Some studies regard the relationship between the two portions as a linear model. For example, Vento et al.84 introduce the metadata into the model and describe the relationship using a general linear function, i.e., f = Mβ + r, where f is the origin feature vector, M is the metadata, β is the learnable coefficient, and r is the residual task-related portion. A similar method is also used in85 to mitigate the confounding bias in an fMRI dataset, where the coefficient β is estimated either on the whole dataset or each fold of the training set. The relationship could also be simply joint, as shown by Aguila et al.86, who train a conditional variational auto-encoder on structural MRI data to disentangle the effect of covariates from the latent feature vectors.
The intuition behind contrastive learning is that in the latent feature space, the distances among feature vectors belonging to the same target class and different sensitive attributes should be minimized, whereas the distances among feature vectors from different target classes and the same sensitive attribute should be maximized. For example, Pakzad et al.19 use a skin tone transformer based on StarGAN to transform the skin tone of the input image and then regularize the L2 norm between the feature vectors extracted from the shared feature extractor. Furthermore, Du et al.87 implement a contrastive learning schema by adding an extra contrastive branch constraining the projected low-dimension feature vector.
There are some other attempts to mitigate unfairness in the in-processing procedure. Inheriting the idea of domain adaptation, FairAdaBN11 reduces unfairness by adding extra adapters to the original model which can adaptively adjust the mean and variance of the feature vector according to the sensitive attribute. Fan et al.88 design a special federated learning setting, where each client in the swarm learning only consists of samples with the same sensitive attribute. Moreover, FairTune89 tries to mitigate unfairness by using parameter-efficient fine-tuning from large-scale pre-trained models. By considering fairness, it can improve fairness in a range of medical image datasets.
The post-processing methods mitigate unfairness by processing the fixed models by calibrating the output of DL models or pruning the model’s parameters.
Calibration uses different prediction thresholds for each subgroup to achieve fairness. Oguguo et al.61 apply the reject option classification algorithm, which believes that unfairness occurs around the decision boundaries. It sets an outcome-changing interval where the output of the unprivileged group is re-modified. The calibration method is one of the most useful mitigation methods as it can be easily adopted on multiple DL models.
Pruning tries to satisfy fairness criteria by distilling the model’s parameters. In their recent work, Wu et al.90 compute the saliency of each neuron in the network and utilize a pruning strategy to remove features associated with a specific group. This approach helps prevent sensitive information from being encoded into the network. Moreover, Marcinkevics et al.79 also use a pruning strategy to deal with unfairness, where the sensitive attribute is unknown. To go further, Huang et al.91 extend the neuron importance measurement proposed in ref. 79, achieving better fairness while reserving model performance.
Fairness datasets in MedIA
To prompt fairness research in MedIA, we collect publicly available datasets with sensitive attributes in Table 3, which are categorized by image modality type, task type, attributes type, and the number of images in each dataset. We hope this Table can benefit the late-comer to find proper data to evaluate their algorithms Table 4.
Full size table
Full size table
Discussion
When adopting AI algorithms in medical applications, clinicians must be aware that, during the development of AI algorithms, most of the methods only focus on the diagnosis performance while ignoring whether the algorithm has biased or unfair utilities towards different subgroups. As a result, clinicians may find that the algorithm tends to underdiagnose specific sub-populations, and the corresponding treatment for each group might also differ. This phenomenon will make the clinician confused about clinical decision-making and wonder why the AI algorithms perform unfairly like that.
Thus, it is important to discover the sources of unfairness in MedIA, not only to help clinicians understand potential biases in the AI algorithms and propose reliable treatment but also to help the AI scientists be aware of the source of unfairness and produce corresponding solutions and design better AI products. Moreover, after clinicians and AI scientists are aware of the sources of unfairness in each application, the government can devise actions focusing on the root reason and prevent the recurrence of unfairness in the future.
Following ref. 92, we categorize the sources of unfairness based on the components of a DL system pipeline, i.e., data, model, and deployment. Figure 7 illustrates the schema of these sources and potential solutions.

From top to bottom: skewed data distribution → aggregate data from multiple datasets; anatomy difference between subgroups → ; annotation differences for each subgroup → using causal image synthesis methods to transfer the input to the synthesis ones with opposite attribute; annotation noise → involve multi-annotators to stabilize annotation; ERM-based model selection which chooses models with the highest overall performance → DTO-based model selection which consider both performance and fairness; spurious correlations between sensitive attributes and diagnosis → removing the effects of the confounder; inherited bias from the pre-train dataset → pruning the pre-trained with fairness constraints; domain gaps between the source dataset and target dataset → using domain adaptation methods to transfer models.
Full size image
Unfairness existing in the data consists of three parts. First, the skewed data distribution of the diagnosis label and the sensitive attributes might cause the insufficient feature representation of the specific group4,93. Second, due to the anatomical differences between different subgroups, the difficulty for DL models to provide precise diagnoses may also vary94. Third, as the clinicians may have different annotation preferences on patients of different attributes95, this annotation inconsistency will confuse the DL model and cause unfairness.
The DL model itself also causes unfairness. The general training process of DL models aims to find the model with the highest overall performance. However, a higher performance might lead to larger subgroup gaps53. Besides, as DL models tend to learn easier but irrelevant correlations between the input image and the output diagnosis, they may attempt to produce the diagnosis based on spurious correlations rather than true medical evidence53. Moreover, some DL models also amplify the unfairness that exists in the data and enlarge the fairness gaps among subgroups96.
With the wide use of pre-trained DL models, unfairness also comes from the deployment. Some pre-trained models inherit bias from the pre-training datasets and perform unfairly on the downstream tasks. On the other hand, the non-neglectable domain gaps among the situations where the model is developed and deployed also affect the performance of the model and cause unfairness.
The Facial recognition (FR) community was aware of unfairness issues, even earlier than the MedIA community97. Research in fair FR aims to achieve equal TPR and FPR of recognition among subgroups with different sexes, ages, hairstyles, emotions, etc. Over the past years, several attempts have been made to align fair MedIA with fair FR, by transferring unfairness mitigation algorithms from FR to MedIA53,54. However, experiments prove that most of the useful methods in fair FR are not applicable in fair MedIA, which attracts people’s attention to the differences between the two areas. Table 5 illustrates the comparison between fair FR and fair MedIA.
Full size table
The largest difference between fair FR and fair MedIA is the variation of image modalities. As most of the images in FR are RGB images, the input in MedIA varies from 2D X-ray images, dermoscopy, and mammography to 3D MRI, and PET/CT. The huge disparity among the multi-modality input and complex types of tasks (classification, segmentation, detection) makes it impossible to find a common solution for all tasks. Besides, the amount of samples in the MedIA dataset is several orders of magnitude smaller than those in facial datasets, which brings more difficulties for robust feature representation. The type of sensitive attribute also varies. While attributes in fair MedIA mainly describe the demographics of a patient, attributes in fair FR focus more on the appearance of a person. This disparity affects the difficulty of attribute recognition. As a result, the composition of MedIA datasets is usually skewed, due to the different morbidity across subgroups. In contrast, there are several specially designed face datasets with balanced attributes for fair FR, such as FairFace97. The lack of balanced medical datasets seriously hinders the benchmark of unfairness mitigation algorithms in fair MedIA.
While AI scientists and clinicians have their understanding of fairness, the gaps between the mathematical definitions and the dilemma in medical scenarios cannot be neglected to achieve health equity.
Most of the current research in AI fairness is conducted on measuring and mitigating unfairness with the mathematical form of fairness, i.e. the numeric differences between manually designed metrics such as DP, AP, EqOdd, etc. However, from the scope of clinicians, equality in numbers does not always mean equity of treatment98. In other words, the performance disparity does not equal unfairness. Forced insistence on numerical equality will destroy the causal relationship between the patients’ metadata (sensitive attributes) and the diagnosis outcome.
To address fairness in AI, we need to decide which sensitive attributes should be evaluated. Generally, AI scientists prefer to analyze the statistical relationship between the target task and the sensitive attribute, i.e. does the model have a biased outcome on this attribute? On the contrary, clinicians pay more attention to the physiological causality between the two terms, for example, will the anatomical difference between the male and the female affect the diagnosis difficulty? This different paradigm of attribute selection also brings gaps between AI scientists and clinicians when they address fairness in MedIA together92.
The choices of fairness metrics also vary between AI fairness and clinical fairness. While AI scientists adopt metrics that are derived from the confusion metrics, clinicians regard some of the metrics as unreasonable. For example, one of the most commonly used metrics in AI fairness, demographic parity, requires that the patients from each subgroup should have the same probability of being predicted as ailing, i.e., (P(hat{Y}=1| A=0)=P(hat{Y}=1| A=1)). However, in practical medical scenarios, where many illnesses are proven to be related to age or sex, the requirement of the same subgroup morbidity is not matched with reality. Furthermore, the diagnosis difficulty may vary across subgroups due to anatomical differences99. In this situation, it is more appropriate for the DL algorithm to have an unequal diagnosis precision due to reasonable medical prior.
Moreover, due to the randomness of DL models, it is nearly impossible to have exactly the same performance among different subgroups. However, in medical applications, a slight fluctuation in the subgroup diagnosis performance is acceptable due to the complexity of the illness. Thus, we need to carefully decide what level of numerical difference means unfairness. Furthermore, unlike utility metrics such as accuracy and area under the receiver-operating curve (AUROC), fairness metrics usually fluctuate along the training procedure and are hard to converge. Therefore, additional efforts need to be made to assess the level of fairness properly.
Recently, foundation models, such as Large Language Model (LLM)100,101, Contrastive Language Image Pre-training (CLIP) and its variants102,103,104,105, and Segment Anything Model (SAM) and its variants106,107,108,109 have attracted people’s attention by their superior zero-shot or few-shot performances on downstream tasks in medical applications. However, as the training sets of these foundation models are usually inaccessible, it is important to ensure whether these models have unbiased utilities on different subgroups before adopting them in healthcare applications.
For example, LLMs, a category of DL models trained with countless corpus from all over the world, might introduce unfairness from the pre-training tasks, or perform unfairly due to the large domain gap between the pre-training task and the fine-tuned downstream tasks (unfairness from deployment)110. Similarly, unfair performances are also witnessed in CLIP models, which try to align semantic information between text and image data to construct an excellent feature extractor111,112. This unfairness might be due to the spurious relations between sensitive attributes and the target label113. SAM is another family of foundation models that focuses on image segmentation tasks, mainly with the help of point or box prompts. As shown in the original SAM paper, the training images of SAM have a strong region preference, i.e., the number of images collected in Europe is larger than that in South America. This bias in geographic distribution is propagated in the fine-tuned version of SAM in medical applications.
In short, most of the large-scale foundation models and language models suffer from different levels of unfairness, due to domain gap, annotation noise, spurious correlation, or inherited bias from the training set. This phenomenon hurts the trustworthiness of DL-based algorithms and must be handled properly. However, due to the huge amount of parameters of these foundation models, it is hard to mitigate unfairness using the aforementioned techniques, as the retraining of foundation models requires heavy computation and a long time. Thus, it is crucial to come up with unfairness mitigation methods aimed at foundation models, including perturbing the feature space114 and editing the input images115.
Addressing fairness in MedIA requires in-depth cooperation among AI scientists, ethicists, and clinicians. In this cooperation, AI scientists should be aware of the limitations of the mathematical form of fairness with the help of ethicists and clinicians, and try to develop new algorithms that can mitigate unfairness effectively. The clinicians could discover the causal relations between illness diagnosis and the metadata of the patients, finding out which type of disparity should be regarded as differences rather than unfairness. Besides, the government can also incorporate fairness considerations into clinical AI guidelines to improve the awareness of fairness in the whole pipeline116. By improving the comprehension of the operation mechanism of the DL models and the clinical context grasping, the researchers can update existing AI governance schemes to promote fairness. While establishing multi-directional communication across various professions may present challenges, it is imperative to exert considerable effort toward addressing fairness in MedIA and safeguarding health equity on a global scale.
In conclusion, this review reveals the importance of assessing fairness in deep learning-based medical image analysis. We describe the basics of group fairness and categorize current studies in fair MedIA into fairness evaluation and unfairness mitigation. Moreover, we address the challenges and opportunities for improving fairness in MedIA. In a word, fairness evaluation and unfairness mitigation is a rapidly growing and promising research field in MedIA, for AI scientists, clinicians, and the power-holder. We must pay more attention to this area to build a fair society for citizens of different sexes, ages, races, and skin tones.
Methods
This review was conducted based on the PRISMA guidelines117.
Search strategy
All the candidate articles were collected by a comprehensive search of four databases, including Scopus, PubMed, arXiv, and Google Scholar using the query conditions: ‘medical fairness’ ∣ ‘fairness in medical image analysis’ ∣ ‘fair medical machine learning’ ∣ “fairness in healthcare’. We limit the publish time from 2015 to 2023 for Scopus and PubMed, and only include the top 200/100 items for ArXiv and Google Scholar, respectively.
After removing duplicated papers, we included all research papers in English. Since this review mainly focuses on methodology, we included papers describing methods for fairness issues in medical image analysis using deep learning algorithms.
For better categorization, we hierarchically split the papers into two classes, fairness evaluation and unfairness mitigation. Each of them was separated into more precise sub-areas accordingly. Besides, we also reported the image modality and datasets used in their paper, tasks and sensitive attributes they worked on, and metrics about fairness they adopted.
Data extraction
For the included studies, we extract information from the following aspects: (1) year of publication; (2) image modality; (3) datasets used; (4) type of task; (5) research area according to taxonomy; (6) sensitive attributes assessed on; (7) metrics used for fairness evaluation. By extracting these data, we hope to help the researcher better understand the routine of new studies about fair MedIA and come up with insights into both fairness evaluation and unfairness mitigation for MedIA.
Data availability
The authors declare that all data supporting the findings of this study are available within the paper.
References
-
Stanley, E. A., Wilms, M., Mouches, P. & Forkert, N. D. Fairness-related performance and explainability effects in deep learning models for brain image analysis. J. Med. Imaging 9, 061102 (2022).
Article Google Scholar
-
Seyyed-Kalantari, L., Zhang, H., McDermott, M. B., Chen, I. Y. & Ghassemi, M. Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations. Nat. Med. 27, 2176–2182 (2021).
Article PubMed PubMed Central Google Scholar
-
Puyol-Antón, E. et al. Fairness in cardiac MR image analysis: an investigation of bias due to data imbalance in deep learning based segmentation. In Medical Image Computing and Computer Assisted Intervention – MICCAI 2021 413–423 (Springer Int. Publ., 2021).
-
Puyol-Antón, E. et al. Fairness in cardiac magnetic resonance imaging: assessing sex and racial bias in deep learning-based segmentation. Front. Cardiovasc. Med. 9, 859310 (2022).
Article PubMed Central Google Scholar
-
Seyyed-Kalantari, L., Liu, G., McDermott, M., Chen, I. Y. & Ghassemi, M. CheXclusion: fairness gaps in deep chest X-ray classifiers. In BIOCOMPUTING 2021: Proc. Pacific Symposium 232–243 (World Scientific, 2020).
-
Ben, G. et al. Algorithmic encoding of protected characteristics in chest X-ray disease detection models. EBioMedicine 89, 104467 (2023).
-
Ribeiro, F., Shumovskaia, V., Davies, T. & Ktena, I. How fair is your graph? Exploring fairness concerns in neuroimaging studies. In Machine Learning for Healthcare Conference 459–478 (PMLR, 2022).
-
Ioannou, S., Chockler, H., Hammers, A., King, A. P. & Initiative, A. D. N. A Study of Demographic Bias in CNN-Based Brain MR Segmentation. In Machine Learning in Clinical Neuroimaging: 5th International Workshop, MLCN 2022, Held in Conjunction with MICCAI 2022, Singapore, September 18, 2022, Proceedings 13–22 (Springer, 2022).
-
Petersen, E. et al. Feature robustness and sex differences in medical imaging: a case study in MRI-based Alzheimer’s disease detection. In International Conference on Medical Image Computing and Computer-Assisted Intervention 88–98 (Springer, 2022).
-
Cherepanova, V., Nanda, V., Goldblum, M., Dickerson, J. P. & Goldstein, T. Technical challenges for training fair neural networks. Preprint at https://doi.org/10.48550/arXiv.2102.06764 (2021).
-
Xu, Z., Zhao, S., Quan, Q., Yao, Q. & Zhou, S. K. Fairadabn: mitigating unfairness with adaptive batch normalization and its application to dermatological disease classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention 307–317 (Springer, 2023).
-
Mehta, R., Shui, C. & Arbel, T. Evaluating the fairness of deep learning uncertainty estimates in medical image analysis. Medical Imaging with Deep Learning 1453–1492 (2023).
-
Larrazabal, A. J., Nieto, N., Peterson, V., Milone, D. H. & Ferrante, E. Gender imbalance in medical imaging datasets produces biased classifiers for computer-aided diagnosis. Proc. Natl Acad. Sci. USA 117, 12592–12594 (2020).
Article PubMed PubMed Central Google Scholar
-
Brown, A. et al. Detecting shortcut learning for fair medical AI using shortcut testing. Nat. Commun. 14, 4314 (2023).
Article PubMed PubMed Central Google Scholar
-
Adeli, E. et al. Representation learning with statistical independence to mitigate bias. In Proc. IEEE/CVF Winter Conference on Applications of Computer Vision, 2513–2523 (IEEE, 2021).
-
Zhang, B. H., Lemoine, B. & Mitchell, M. Mitigating unwanted biases with adversarial learning. In Proc. 2018 AAAI/ACM Conference on AI, Ethics, and Society, 335–340 (ACM, 2018).
-
Deng, W., Zhong, Y., Dou, Q. & Li, X. On fairness of medical image classification with multiple sensitive attributes via learning orthogonal representations. In International Conference on Information Processing in Medical Imaging 158–169 (Springer, 2023).
-
Li, X., Cui, Z., Wu, Y., Gu, L. & Harada, T. Estimating and improving fairness with adversarial learning. Preprint at https://doi.org/10.48550/arXiv.2103.04243 (2021).
-
Pakzad, A., Abhishek, K. & Hamarneh, G. CIRCLe: color invariant representation learning for unbiased classification of skin lesions. In Proc. 17th European Conference on Computer Vision (ECCV) – ISIC Skin Image Analysis Workshop, (Springer, 2022).
-
Yang, J., Soltan, A. A., Eyre, D. W. & Clifton, D. A. Algorithmic fairness and bias mitigation for clinical machine learning with deep reinforcement learning. Nat. Mach. Intell. 5, 884–894 (2023).
Article PubMed Central Google Scholar
-
Yang, J., Soltan, A. A., Eyre, D. W., Yang, Y. & Clifton, D. A. An adversarial training framework for mitigating algorithmic biases in clinical machine learning. NPJ Digit. Med. 6, 55 (2023).
Article PubMed Central Google Scholar
-
Celeste, C. et al. Ethnic disparity in diagnosing asymptomatic bacterial vaginosis using machine learning. NPJ Digit. Med. 6, 211 (2023).
Article PubMed Central Google Scholar
-
Ricci Lara, M. A., Mosquera, C., Ferrante, E. & Echeveste, R. Towards unraveling calibration biases in medical image analysis. In Workshop on Clinical Image-Based Procedures 132–141 (Springer, 2023).
-
Beauchamp, T. L. Methods and principles in biomedical ethics. J. Med. Ethics 29, 269–274 (2003).
Article PubMed Central Google Scholar
-
Liu, M. et al. A translational perspective towards clinical ai fairness. NPJ Digit. Med. 6, 172 (2023).
Article PubMed Central Google Scholar
-
Srivastava, M., Heidari, H. & Krause, A. Mathematical notions vs. human perception of fairness: a descriptive approach to fairness for machine learning. In Proc. 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2459–2468 (ACM, 2019).
-
Jones, N. et al. Building understanding of fairness, equality and good relations. In Equality and Human Rights Commission Research Report 53 (2010).
-
Green, C. R. et al. The unequal burden of pain: confronting racial and ethnic disparities in pain. Pain Med. 4, 277–294 (2003).
Article Google Scholar
-
Anderson, K. O., Green, C. R. & Payne, R. Racial and ethnic disparities in pain: causes and consequences of unequal care. J. Pain 10, 1187–1204 (2009).
Article Google Scholar
-
Mittermaier, M., Raza, M. M. & Kvedar, J. C. Bias in ai-based models for medical applications: challenges and mitigation strategies. NPJ Digit. Med. 6, 113 (2023).
Article PubMed Central Google Scholar
-
Currie, G. & Hawk, K. E. Ethical and legal challenges of artificial intelligence in nuclear medicine. In Seminars in Nuclear Medicine, Vol. 51 120–125 (Elsevier, 2021).
-
Batra, A. M. & Reche, A. A New Era of Dental Care: Harnessing Artificial Intelligence for Better Diagnosis and Treatment. Cureus. 15, e49319 (2023).
-
Dwork, C., Hardt, M., Pitassi, T., Reingold, O. & Zemel, R. Fairness through awareness. In Proc. 3rd Innovations in Theoretical Computer Science Conference, 214–226 (ACM, 2012).
-
Barocas, S., Hardt, M. & Narayanan, A. Fairness and Machine Learning: Limitations and Opportunities (MIT Press, 2023).
-
Lahoti, P. et al. Fairness without demographics through adversarially reweighted learning. Adv. Neural Inf. Process. Syst. 33, 728–740 (2020).
Google Scholar
-
Kusner, M. J., Loftus, J., Russell, C. & Silva, R. Counterfactual fairness. Adv. Neural Inf. Process. Syst. 30 (2017).
-
Mbakwe, A. B., Lourentzou, I., Celi, L. A. & Wu, J. T. Fairness metrics for health ai: we have a long way to go. Ebiomedicine 90, 104525 (2023).
-
Bird, S. et al. Fairlearn: A Toolkit for Assessing and Improving Fairness in AI. Tech. Rep. MSR-TR-2020-32 (Microsoft, 2020).
-
Wang, M. & Deng, W. Mitigating bias in face recognition using skewness-aware reinforcement learning. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9322–9331, (IEEE, 2020).
-
Bercea, C. I. et al. Bias in unsupervised anomaly detection in brain MRI. In Workshop on Clinical Image-Based Procedures 122–131 (Springer, 2023).
-
Yuan, C., Linn, K. A. & Hubbard, R. A. Algorithmic fairness of machine learning models for Alzheimer disease progression. JAMA Netw. Open 6, e2342203–e2342203 (2023).
Article PubMed Central Google Scholar
-
Dang, V. N. et al. Auditing unfair biases in CNN-based diagnosis of Alzheimer’s disease. In Workshop on Clinical Image-Based Procedures 172–182 (Springer, 2023).
-
Klingenberg, M. et al. Higher performance for women than men in MRI-based Alzheimer’s disease detection. Alzheimers Res. Ther. 15, 84 (2023).
Article PubMed Central Google Scholar
-
Huti, M., Lee, T., Sawyer, E. & King, A. P. An investigation into race bias in random forest models based on breast DCE-MRI derived radiomics features. In Workshop on Clinical Image-Based Procedures 225–234 (Springer, 2023).
-
Schwartz, C. et al. Association of population screening for breast cancer risk with use of mammography among women in medically underserved racial and ethnic minority groups. JAMA Netw. Open 4, e2123751–e2123751 (2021).
Article PubMed Central Google Scholar
-
Salahuddin, Z. et al. From head and neck tumour and lymph node segmentation to survival prediction on pet/ct: an end-to-end framework featuring uncertainty, fairness, and multi-region multi-modal radiomics. Cancers 15, 1932 (2023).
Article PubMed Central Google Scholar
-
Kinyanjui, N. M. et al. Fairness of classifiers across skin tones in dermatology. In International Conference on Medical Image Computing and Computer-Assisted Intervention 320–329 (Springer, 2020).
-
Kalb, T. et al. Revisiting skin tone fairness in dermatological lesion classification. In Workshop on Clinical Image-Based Procedures 246–255 (Springer, 2023).
-
Piçarra, C. & Glocker, B. Analysing race and sex bias in brain age prediction. In Workshop on Clinical Image-Based Procedures 194–204 (Springer, 2023).
-
Du, Y., Xue, Y., Dharmakumar, R. & Tsaftaris, S. A. Unveiling fairness biases in deep learning-based brain MRI reconstruction. In Workshop on Clinical Image-Based Procedures 102–111 (Springer, 2023).
-
Sadafi, A., Hehr, M., Navab, N. & Marr, C. A study of age and sex bias in multiple instance learning based classification of acute myeloid leukemia subtypes. In Workshop on Clinical Image-Based Procedures 256–265 (Springer, 2023).
-
Lee, T. et al. An investigation into the impact of deep learning model choice on sex and race bias in cardiac MR segmentation. In Workshop on Clinical Image-Based Procedures 215–224 (Springer, 2023).
-
Zong, Y., Yang, Y. & Hospedales, T. MEDFAIR: benchmarking fairness for medical imaging. In International Conference on Learning Representations (ICLR) (2023).
-
Zhang, H. et al. Improving the fairness of chest x-ray classifiers. In Conference on Health, Inference, and Learning 204–233 (PMLR, 2022).
-
Ganz, M., Holm, S. H. & Feragen, A. Assessing bias in medical AI. In Workshop on Interpretable ML in Healthcare at International Conference on Machine Learning (ICML) (ACM, 2021).
-
Campos, A. Gender differences in imagery. Pers. Individ. Differ. 59, 107–111 (2014).
Article Google Scholar
-
Jiménez-Sánchez, A., Juodelyte, D., Chamberlain, B. & Cheplygina, V. Detecting shortcuts in medical images-a case study in chest x-rays. In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI) 1–5 (IEEE, 2023).
-
Jones, C., Roschewitz, M. & Glocker, B. The role of subgroup separability in group-fair medical image classification. In Medical Image Computing and Computer Assisted Intervention – MICCAI 2023 179–188 (Springer, 2023).
-
Weng, N., Bigdeli, S., Petersen, E. & Feragen, A. Are sex-based physiological differences the cause of gender bias for chest X-ray diagnosis? In Workshop on Clinical Image-Based Procedures 142–152 (Springer, 2023).
-
Lu, C., Lemay, A., Hoebel, K. & Kalpathy-Cramer, J. Evaluating subgroup disparity using epistemic uncertainty in mammography. In Workshop on Interpretable Machine Learning in Healthcare at International Conference on Machine Learning (ICML) (ACM, 2021).
-
Oguguo, T. et al. A comparative study of fairness in medical machine learning. In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI) 1–5 (IEEE, 2023).
-
Bissoto, A., Fornaciali, M., Valle, E. & Avila, S. (De) Constructing bias on skin lesion datasets. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (IEEE, 2019).
-
Bissoto, A., Valle, E. & Avila, S. Debiasing skin lesion datasets and models? Not so fast. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 740–741 (IEEE, 2020).
-
Yuan, H. et al. EdgeMixup: embarrassingly simple data alteration to improve Lyme disease lesion segmentation and diagnosis fairness. In International Conference on Medical Image Computing and Computer-Assisted Intervention 374–384 (Springer, 2023).
-
Wachinger, C. et al. Detect and correct bias in multi-site neuroimaging datasets. Med. Image Anal. 67, 101879 (2021).
Article Google Scholar
-
Wu, C. et al. De-identification and obfuscation of gender attributes from retinal scans. In Workshop on Clinical Image-Based Procedures 91–101 (Springer, 2023).
-
Yao, R., Cui, Z., Li, X. & Gu, L. Improving fairness in image classification via sketching. In Workshop on Trustworthy and Socially Responsible Machine Learning, NeurIPS 2022 https://openreview.net/forum?id=Rq2vt3tnAK9 (2022).
-
Wang, R., Chaudhari, P. & Davatzikos, C. Bias in machine learning models can be significantly mitigated by careful training: evidence from neuroimaging studies. Proc. Natl. Acad. Sci. USA 120, e2211613120 (2023).
Article PubMed Central Google Scholar
-
Zhou, Y. et al. Radfusion: benchmarking performance and fairness for multimodal pulmonary embolism detection from CT and EHR. Preprint at https://arxiv.org/abs/2111.11665 (2021).
-
Joshi, N. & Burlina, P. AI fairness via domain adaptation. Preprint at https://doi.org/10.48550/arXiv.2104.01109 (2021).
-
Burlina, P., Joshi, N., Paul, W., Pacheco, K. D. & Bressler, N. M. Addressing artificial intelligence bias in retinal diagnostics. Transl. Vis. Sci. Technol. 10, 13–13 (2021).
Article PubMed Central Google Scholar
-
Pombo, G. et al. Equitable modelling of brain imaging by counterfactual augmentation with morphologically constrained 3d deep generative models. Med. Image Anal. 84, 102723 (2023).
Article PubMed Central Google Scholar
-
Zhao, Q., Adeli, E. & Pohl, K. M. Training confounder-free deep learning models for medical applications. Nat. Commun. 11, 1–9 (2020).
Article Google Scholar
-
Abbasi-Sureshjani, S., Raumanns, R., Michels, B. E., Schouten, G. & Cheplygina, V. Risk of training diagnostic algorithms on data with demographic bias. In Interpretable and Annotation-Efficient Learning for Medical Image Computing: Third International Workshop, iMIMIC 2020, Second International Workshop, MIL3ID 2020, and 5th International Workshop, LABELS 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 4–8, 2020, Proceedings, Vol. 3 183–192 (Springer, 2020).
-
Bevan, P. J. & Atapour-Abarghouei, A. Detecting melanoma fairly: skin tone detection and debiasing for skin lesion classification. In MICCAI Workshop on Domain Adaptation and Representation Transfer 1–11 (Springer, 2022).
-
Barron, J. T. A generalization of Otsu’s method and minimum error thresholding. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V, Vol. 16 455–470 (Springer, 2020).
-
Correa, R. et al. A systematic review of ‘fair’ AI model development for image classification and prediction. J. Med. Biol. Eng. 42, 816–827 (2022).
Article Google Scholar
-
Stanley, E. A., Wilms, M. & Forkert, N. D. Disproportionate subgroup impacts and other challenges of fairness in artificial intelligence for medical image analysis. In Workshop on the Ethical and Philosophical Issues in Medical Imaging 14–25 (Springer, 2022).
-
Marcinkevics, R., Ozkan, E. & Vogt, J. E. Debiasing deep chest x-ray classifiers using intra-and post-processing methods. In Machine Learning for Healthcare Conference 504–536 (PMLR, 2022).
-
Luo, L., Xu, D., Chen, H., Wong, T.-T. & Heng, P.-A. Pseudo bias-balanced learning for debiased chest x-ray classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention 621–631 (Springer, 2022).
-
Lin, M. et al. Improving model fairness in image-based computer-aided diagnosis. Nat. Commun. 14, 6261 (2023).
Article PubMed PubMed Central Google Scholar
-
Kearns, M., Neel, S., Roth, A. & Wu, Z. S. Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In International Conference on Machine Learning 2564–2572 (PMLR, 2018).
-
Sarhan, M. H., Navab, N., Eslami, A. & Albarqouni, S. Fairness by learning orthogonal disentangled representations. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX Vol. 16 746–761 (Springer, 2020).
-
Vento, A., Zhao, Q., Paul, R., Pohl, K. M. & Adeli, E. A penalty approach for normalizing feature distributions to build confounder-free models. In International Conference on Medical Image Computing and Computer-Assisted Intervention 387–397 (Springer, 2022).
-
More, S., Eickhoff, S. B., Caspers, J. & Patil, K. R. Confound removal and normalization in practice: a neuroimaging based sex prediction case study. In Machine Learning and Knowledge Discovery in Databases. Applied Data Science and Demo Track: European Conference, ECML PKDD 2020, Ghent, Belgium, September 14–18, 2020, Proceedings, Part V 3–18 (Springer, 2021).
-
Lawry Aguila, A., Chapman, J., Janahi, M. & Altmann, A. Conditional VAEs for confound removal and normative modelling of neurodegenerative diseases. In International Conference on Medical Image Computing and Computer-Assisted Intervention 430–440 (Springer, 2022).
-
Du, S., Hers, B., Bayasi, N., Hamarneh, G. & Garbi, R. FairDisCo: Fairer AI in dermatology via disentanglement contrastive learning. In European Conference on Computer Vision 185–202 (Springer, 2022).
-
Fan, D., Wu, Y. & Li, X. On the fairness of swarm learning in skin lesion classification. In Clinical Image-Based Procedures, Distributed and Collaborative Learning, Artificial Intelligence for Combating COVID-19 and Secure and Privacy-Preserving Machine Learning: 10th Workshop, CLIP 2021, Second Workshop, DCL 2021, First Workshop, LL-COVID19 2021, and First Workshop and Tutorial, PPML 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, September 27 and October 1, 2021, Proceedings, Vol. 2 120–129 (Springer, 2021).
-
Dutt, R., Bohdal, O., Tsaftaris, S. A. & Hospedales, T. Fairtune: Optimizing parameter efficient fine tuning for fairness in medical image analysis. In International Conference on Learning Representations (2024).
-
Wu, Y., Zeng, D., Xu, X., Shi, Y. & Hu, J. Fairprune: achieving fairness through pruning for dermatological disease diagnosis. In International Conference on Medical Image Computing and Computer-Assisted Intervention 743–753 (Springer, 2022).
-
Huang, Y.-Y., Chiuwanara, V., Lin, C.-H. & Kuo, P.-C. Mitigating bias in MRI-based Alzheimer’s disease classifiers through pruning of deep neural networks. In Workshop on Clinical Image-Based Procedures 163–171 (Springer, 2023).
-
Ricci Lara, M. A., Echeveste, R. & Ferrante, E. Addressing fairness in artificial intelligence for medical imaging. Nat. Commun. 13, 4581 (2022).
Article PubMed Central Google Scholar
-
Clark, K. et al. The cancer imaging archive (tcia): maintaining and operating a public information repository. J. Digit. Imaging. 26, 1045–1057 (2013).
Article PubMed Central Google Scholar
-
Webb, E. K., Etter, J. A. & Kwasa, J. A. Addressing racial and phenotypic bias in human neuroscience methods. Nat. Neurosci. 25, 410–414 (2022).
Article PubMed Central Google Scholar
-
Berhane, A. & Enquselassie, F. Patients’ preferences for attributes related to health care services at hospitals in Amhara region, northern Ethiopia: a discrete choice experiment. Patient Prefer. Adherence.1293–1301 (2015).
-
Wang, A. & Russakovsky, O. Directional bias amplification. In International Conference on Machine Learning 10882–10893 (PMLR, 2021).
-
Karkkainen, K. & Joo, J. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. In Proc. IEEE/CVF Winter Conference on Applications of Computer Vision 1548–1558 (2021).
-
McCradden, M. D., Joshi, S., Mazwi, M. & Anderson, J. A. Ethical limitations of algorithmic fairness solutions in health care machine learning. Lancet Digit. Health. 2, e221–e223 (2020).
Article Google Scholar
-
Fairbairn, T. A. et al. Sex differences in coronary computed tomography angiography–derived fractional flow reserve: lessons from advance. Cardiovasc. Imaging 13, 2576–2587 (2020).
Google Scholar
-
Lee, J. et al. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2020).
Article Google Scholar
-
Xu, M. Medicalgpt: training medical GPT model. https://github.com/shibing624/MedicalGPT (2023).
-
Radford, A. et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning 8748–8763 (PMLR, 2021).
-
Eslami, S., Meinel, C. & De Melo, G. Pubmedclip: how much does clip benefit visual question answering in the medical domain? In Findings of the Association for Computational Linguistics: EACL 2023 1181–1193 (ACL, 2023).
-
Lin, W. et al. Pmc-clip: contrastive language-image pre-training using biomedical documents. In International Conference on Medical Image Computing and Computer-Assisted Intervention 525–536 (Springer, 2023).
-
Lai, H. et al. Carzero: Cross-attention alignment for radiology zero-shot classification. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 11137–11146 (IEEE, 2024).
-
Kirillov, A. et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR) 4015–4026 (2023).
-
Ma, J. et al. Segment anything in medical images. Nat. Commun. 15, 654 (2024).
Article PubMed Central Google Scholar
-
Quan, Q., Tang, F., Xu, Z., Zhu, H. & Zhou, S. K. Slide-SAM: medical SAM meets sliding window. Medical Imaging with Deep Learning https://doi.org/10.48550/arXiv.2311.10121 (2024).
-
Wang, H. et al. Sam-med3d: towards general-purpose segmentation models for volumetric medical images. Preprint at https://arxiv.org/abs/2310.15161 (2024).
-
Li, Y., Du, M., Song, R., Wang, X. & Wang, Y. A survey on fairness in large language models. Preprint at https://doi.org/10.48550/arXiv.2308.10149 (2023).
-
Wang, J., Liu, Y. & Wang, X. E. Are gender-neutral queries really gender-neutral? Mitigating gender bias in image search. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing 1995–2008 (2021).
-
Berg, H. et al. A prompt array keeps the bias away: Debiasing vision-language models with adversarial learning. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) 806–822 (2022).
-
Hendricks, L. A., Burns, K., Saenko, K., Darrell, T. & Rohrbach, A. Women also snowboard: overcoming bias in captioning models. In Proc. European Conference on Computer Vision (ECCV) 771–787 (2018).
-
Xu, Z., Tang, F., Quan, Q., Yao, Q. & Zhou, S. K. Apple: adversarial privacy-aware perturbations on latent embedding for unfairness mitigation. Preprint at https://arxiv.org/pdf/2403.05114 (2024).
-
Jin, R., Deng, W., Chen, M. & Li, X. Debiased Noise Editing on Foundation Models for Fair Medical Image Classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention 164–174 (2024).
-
Collins, G. S. et al. Protocol for development of a reporting guideline (tripod-ai) and risk of bias tool (probast-ai) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ Open 11, e048008 (2021).
Article PubMed Central Google Scholar
-
Takkouche, B. & Norman, G. Prisma statement. Epidemiology 22, 128 (2011).
Article Google Scholar
-
Zafar, M. B., Valera, I., Rogriguez, M. G. & Gummadi, K. P. Fairness constraints: mechanisms for fair classification. In Artificial Intelligence and Statistics 962–970 (PMLR, 2017).
-
Hardt, M., Price, E. & Srebro, N. Equality of opportunity in supervised learning. Adv. Neural Inf. Process. Syst. 29 (2016).
-
Liang, H., Ni, K. & Balakrishnan, G. Visualizing chest X-ray dataset biases using GANs. Medical Imaging with Deep Learning, Short Paper Track https://openreview.net/forum?id=bFb3V8ALx4W (2023).
-
Gronowski, A., Paul, W., Alajaji, F., Gharesifard, B. & Burlina, P. Rényi fair information bottleneck for image classification. In 2022 17th Canadian Workshop on Information Theory (CWIT) 11–15 (IEEE, 2022).
-
Irvin, J. et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proc. AAAI Conference on Artificial Intelligence, Vol. 33 590–597 (AAAI, 2019).
-
Wang, X. et al. Chestx-ray8: hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 2097–2106 (2017).
-
Johnson, A. E. et al. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 6, 1–8 (2019).
Article Google Scholar
-
Bustos, A., Pertusa, A., Salinas, J.-M. & De La Iglesia-Vaya, M. Padchest: a large chest x-ray image dataset with multi-label annotated reports. Med. Image Anal. 66, 101797 (2020).
Article PubMed Google Scholar
-
Borghesi, A. & Maroldi, R. COVID-19 outbreak in Italy: experimental chest x-ray scoring system for quantifying and monitoring disease progression. La Radiol. Med. 125, 509–513 (2020).
Article Google Scholar
-
Signoroni, A. et al. Bs-net: learning COVID-19 pneumonia severity on a large chest x-ray dataset. Med. Image Anal. 71, 102046 (2021).
Article PubMed Central Google Scholar
-
Shiraishi, J. et al. Development of a digital image database for chest radiographs with and without a lung nodule: receiver operating characteristic analysis of radiologists’ detection of pulmonary nodules. Am. J. Roentgenol. 174, 71–74 (2000).
Article Google Scholar
-
Cohen, J. P. et al. Covid-19 image data collection: Prospective predictions are the future. Preprint at https://doi.org/10.59275/j.melba.2020-48g7 (2020).
-
Jaeger, S. et al. Two public chest x-ray datasets for computer-aided screening of pulmonary diseases. Quant. Imaging Med. Surg. 4, 475 (2014).
PubMed Central Google Scholar
-
Kramer, B. S., Gohagan, J., Prorok, P. C. & Smart, C. A national cancer institute sponsored screening trial for prostatic, lung, colorectal, and ovarian cancers. Cancer 71, 589–593 (1993).
Article Google Scholar
-
Nguyen, H. Q. et al. VinDR-CXR: an open dataset of chest x-rays with radiologist’s annotations. Sci. Data 9, 429 (2022).
Article PubMed PubMed Central Google Scholar
-
Ettinger, D. S. et al. Non–small cell lung cancer, version 5.2017, NCCN clinical practice guidelines in oncology. J. Natl. Compr. Cancer Netw. 15, 504–535 (2017).
Article Google Scholar
-
Shakouri, S. et al. Covid19-ct-dataset: an open-access chest CT image repository of 1000+ patients with confirmed COVID-19 diagnosis. BMC Res. Notes 14, 1–3 (2021).
Article Google Scholar
-
Team, N. L. S. T. R. et al. The national lung screening trial: overview and study design. Radiology 258, 243 (2011).
Article Google Scholar
-
Pedrosa, J. et al. Lndb: a lung nodule database on computed tomography. Preprint at https://doi.org/10.48550/arXiv.1911.08434 (2019).
-
Afshar, P. et al. Covid-ct-md, covid-19 computed tomography scan dataset applicable in machine learning and deep learning. Sci. Data 8, 121 (2021).
Article PubMed Central Google Scholar
-
Heller, N. et al. The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes. Preprint at https://doi.org/10.48550/arXiv.1904.00445 (2019).
-
Bejarano, T., De Ornelas-Couto, M. & Mihaylov, I. B. Longitudinal fan-beam computed tomography dataset for head-and-neck squamous cell carcinoma patients. Med. Phys. 46, 2526–2537 (2019).
Article PubMed Central Google Scholar
-
Cao, F. et al. Image database for digital hand atlas. In Medical Imaging 2003: PACS and Integrated Medical Information Systems: Design and Evaluation, Vol. 5033 461–470 (SPIE, 2003).
-
Yan, K., Wang, X., Lu, L. & Summers, R. M. Deeplesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning. J. Med. Imaging 5, 036501 (2018).
Article Google Scholar
-
Study, T. A.-R. E. D. et al. The age-related eye disease study (AREDS): design implications AREDS report no. 1. Control. Clin. Trials 20, 573–600 (1999).
Article Google Scholar
-
Kovalyk, O. et al. Papila: Dataset with fundus images and clinical data of both eyes of the same patient for glaucoma assessment. Sci. Data 9, 291 (2022).
Article PubMed Central Google Scholar
-
Díaz, M. et al. Automatic segmentation of the foveal avascular zone in ophthalmological oct-a images. PLoS ONE 14, e0212364 (2019).
Article PubMed Central Google Scholar
-
He, Y. et al. Retinal layer parcellation of optical coherence tomography images: data resource for multiple sclerosis and healthy controls. Data Brief 22, 601–604 (2019).
Article Google Scholar
-
Farsiu, S. et al. Quantitative classification of eyes with and without intermediate age-related macular degeneration using optical coherence tomography. Ophthalmology 121, 162–172 (2014).
Article Google Scholar
-
Kwitt, R., Vasconcelos, N., Razzaque, S. & Aylward, S. Localizing target structures in ultrasound video–a phantom study. Med. Image Anal. 17, 712–722 (2013).
Article PubMed Central Google Scholar
-
Bernard, O. et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE Trans. Med. Imaging 37, 2514–2525 (2018).
Article Google Scholar
-
Petersen, S. E. et al. UK Biobank’s cardiovascular magnetic resonance protocol. J. Cardiovasc. Magn. Reson. 18, 1–7 (2015).
Google Scholar
-
consortium, A.- The ADHD-200 consortium: a model to advance the translational potential of neuroimaging in clinical neuroscience. Front. Syst. Neurosci. 6, 62 (2012).
Article Google Scholar
-
Marcus, D. S. et al. Open access series of imaging studies (OASIS): cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. J. Cogn. Neurosci. 19, 1498–1507 (2007).
Article Google Scholar
-
Di Martino, A. et al. The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 19, 659–667 (2014).
Article Google Scholar
-
Marek, K. et al. The Parkinson progression marker initiative (PPMI). Prog. Neurobiol. 95, 629–635 (2011).
Article PubMed Central Google Scholar
-
Menze, B. H. et al. The multimodal brain tumor image segmentation benchmark (brats). IEEE Trans. Med. Imaging 34, 1993–2024 (2014).
Article PubMed Central Google Scholar
-
Frazier, J. A. et al. Diagnostic and sex effects on limbic volumes in early-onset bipolar disorder and schizophrenia. Schizophr. Bull. 34, 37–46 (2008).
Article Google Scholar
-
Shafto, M. A. et al. The Cambridge Centre for Ageing and Neuroscience (cam-can) study protocol: a cross-sectional, lifespan, multidisciplinary examination of healthy cognitive ageing. BMC Neurol. 14, 1–25 (2014).
Article Google Scholar
-
Milham, M. et al. The International Neuroimaging Data-sharing Initiative (INDI) and the functional connectomes project. In 17th Annual Meeting of the Organization for Human Brain Mapping (2011).
-
Jack Jr, C. R. et al. The Alzheimer’s disease neuroimaging initiative (ADNI): Mri methods. J. Magn. Reson. Imaging 27, 685–691 (2008).
Article Google Scholar
-
Karcher, N. R. & Barch, D. M. The ABCD study: understanding the development of risk for mental and physical health outcomes. Neuropsychopharmacology 46, 131–142 (2021).
Article Google Scholar
-
Codella, N. et al. Skin lesion analysis toward melanoma detection 2018: a challenge hosted by the International Skin Imaging Collaboration (ISIC). Preprint at https://doi.org/10.48550/arXiv.1902.03368 (2019).
-
Rotemberg, V. et al. A patient-centric dataset of images and metadata for identifying melanomas using clinical context. Sci. Data 8, 34 (2021).
Article PubMed PubMed Central Google Scholar
-
Groh, M. et al. Evaluating deep neural networks trained on clinical images in dermatology with the Fitzpatrick 17k dataset. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 1820–1828 (2021).
-
Groh, M., Harris, C., Daneshjou, R., Badri, O. & Koochek, A. Towards transparency in dermatology image datasets with skin tone annotations by experts, crowds, and an algorithm. Proc. ACM Hum.-Comput. Interact. 6, 1–26 (2022).
Article Google Scholar
-
Ganin, Y. & Lempitsky, V. Unsupervised domain adaptation by backpropagation. In International Conference on Machine Learning 1180–1189 (PMLR, 2015).
-
Creager, E. et al. Flexibly fair representation learning by disentanglement. International conference on machine learning 1436–1445 (PMLR, 2019).
-
Chuang, C.-Y., Robinson, J., Lin, Y.-C., Torralba, A. & Jegelka, S. Debiased contrastive learning. Adv. Neural Inf. Process. Syst. 33, 8765–8775 (2020).
Google Scholar
-
Jungo, A. & Reyes, M. Assessing reliability and challenges of uncertainty estimations for medical image segmentation. Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part II, Vol. 22 48–56 (Springer, 2019).
-
Liu, Z., Luo, P., Wang, X. & Tang, X. Deep learning face attributes in the wild. In Proc. IEEE International Conference on Computer Vision 3730–3738 (2015).
-
Tian, Y. et al. FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling. International Conference on Learning Representations (ICLR) (2024).
-
Borgwardt, K. M. et al. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 22, e49–e57 (2006).
Article Google Scholar
Download references
Acknowledgements
We thank Yongshuo Zong from the University of Edinburgh for his constructive suggestions. This paper is supported by the Natural Science Foundation of China under Grant 62271465, the Suzhou Basic Research Program under Grant SYG202338, and the Open Fund Project of Guangdong Academy of Medical Sciences, China (No. YKY-KF202206).
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and permissions
About this article

Cite this article
Xu, Z., Li, J., Yao, Q. et al. Addressing fairness issues in deep learning-based medical image analysis: a systematic review. npj Digit. Med. 7, 286 (2024). https://doi.org/10.1038/s41746-024-01276-5
Download citation
-
Received:
-
Accepted:
-
Published:
-
DOI: https://doi.org/10.1038/s41746-024-01276-5
Related Posts