March 11, 2025 ・ Press Release Cutting-edge AI solutions for smarter, faster and more efficient computing Revolutionary AI performance: World’s first 19 " 2U edge AI computer with 600W GPU, PCIe ® 5.0, and advanced security Next-gen industrial power: Dual-CPU edge server with Intel ® Xeon ® , up to 4TB DDR5 and hot-swappable

How to Set Up and Optimize DeepSeek Locally | Built In
DeepSeek is a powerful AI model designed for deep learning applications, offering flexibility in local deployment for research, experimentation and production use. This guide covers everything you need to know about the hardware requirements, system configuration, GUI setup, and performance optimizations for running DeepSeek efficiently on different operating systems.
5 Steps to Install DeepSeek on Mac
- Install homebrew and dependencies.
- Set up a virtual environment.
- Install DeepSeek and vLLM.
- Run DeepSeek model with MPS.
- Install and run a GUI interface.
Understanding DeepSeek and System Requirements
DeepSeek is a large-scale AI model for tasks such as natural language processing and code generation. Running it locally provides greater control over data privacy, latency, and model customization, but also requires sufficient hardware resources.
Minimum Hardware Requirements
- GPU: NVIDIA RTX 3090 or equivalent (24GB VRAM recommended)
- CPU: Intel i7 (10th Gen) or AMD Ryzen 7 equivalent
- RAM: 32GB (64GB recommended for large models)
- Storage: At least 512GB SSD (NVMe preferred)
Optimal Setup for Best Performance
- GPU: NVIDIA A100 or RTX 4090 (48GB VRAM for larger models)
- CPU: AMD Threadripper or Intel Xeon (high core count)
- RAM: 128GB+ for handling large data sets in memory
- Storage: 2TB NVMe SSD + additional HDD for backups
DeepSeek models are primarily designed for Linux-based cloud environments with NVIDIA GPUs, but you can still install and run them on a Mac (Apple Silicon) and PC (Windows/Linux) with some workarounds. Below are the best methods for setting up DeepSeek locally with a graphical user interface (GUI).
More on AIWhat Is Artificial Intelligence (AI)?
Installing DeepSeek Locally on a Mac with a GUI
Challenges for Mac, include:
- DeepSeek models require CUDA (NVIDIA GPUs), which Apple Silicon does not support.
- You need to use Metal Performance Shaders (MPS) or CPU-based inference instead of CUDA.
- Performance will be much slower without a dedicated GPU.
Step 1: Install Homebrew and Dependencies
If you haven’t installed Homebrew, do so first:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"This command installs Homebrew, a package manager for macOS and Linux. Here’s what it does in simple terms:
/bin/bash -c: Runs a command inside the Bash shell.$(...): Execute the command inside the parentheses.curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh: Downloads the installation script for Homebrew from GitHub and runs it.
Essentially, this command fetches and runs the Homebrew installer script automatically, making it easy to install Homebrew without manual steps.
Then, install the required dependencies:
brew install cmake protobuf git-lfsThis command installs CMake, Protobuf and Git LFS using Homebrew on macOS or Linux. Here’s what each part does:
brew install: Uses Homebrew to install software packages.cmake: A tool that helps generate build files for compiling software.protobuf: Stands for Protocol Buffers, used for serializing structured data, often in machine learning and APIs.git-lfs: Short for Git Large File Storage, helps manage large files in Git repositories.
This command ensures these essential development tools are installed.
Step 2: Set Up a Virtual Environment
Create a virtual environment to avoid conflicts:
python3 -m venv deepseek_env source deepseek_env/bin/activate pip install --upgrade pipStep 3: Install DeepSeek Model and vLLM
DeepSeek works best with vLLM, which supports metal performance shaders (MPS) on macOS:
pip install vllm torch transformers accelerateThis command installs several Python packages using pip, a package manager for Python. Here’s what each part does:
pip install: Installs Python libraries.vllm: A high-performance inference engine for running large language models efficiently.torch: The core PyTorch library, used for deep learning and neural network computations.transformers: A library from Hugging Face for working with pre-trained models like GPT and DeepSeek.accelerate: Optimizes deep learning model execution, enabling efficient multi-GPU and mixed precision training.
This command ensures you have all the necessary tools for running AI models efficiently.
Then, install DeepSeek models:
pip install deepseek-aiStep 4: Run DeepSeek Model with MPS (Apple Silicon)
from transformers import AutoModelForCausalLM, AutoTokenizer import torch model_id = "deepseek-ai/deepseek-coder-6.7B" device = "mps" if torch.backends.mps.is_available() else "cpu" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained(model_id).to(device) prompt = "Explain the theory of relativity in simple terms." inputs = tokenizer(prompt, return_tensors="pt").to(device) outputs = model.generate(**inputs, max_length=100) print(tokenizer.decode(outputs[0], skip_special_tokens=True)) This Python script loads and runs DeepSeek-Coder 6.7B, an AI model for text generation. Here’s a breakdown:
1. Imports Necessary Libraries
transformers: Handles model and tokenizer loading.torch: Used for tensor computation and hardware acceleration.
2. Sets Up Model and Device
model_id: Specifies the DeepSeek-Coder model.device: Uses Apple Silicon’s MPS (Metal Performance Shaders) if available, otherwise defaults to CPU.
3. Loads Tokenizer & Model
- The tokenizer converts text into a format the model understands.
- The model is loaded onto the specified device.
4. Processes Input & Generates Output
- The input prompt
“Explain the theory of relativity in simple terms.”is tokenized. - The model generates text based on the input.
5. Decodes and Prints Output
The output is converted from tokens back to human-readable text and displayed.
This script allows text-based AI inference on local hardware, making it useful for code completion, content generation, and more.
Step 5: Install and Run a GUI Interface
For an easy-to-use interface, install Text Generation Web UI:
git clone https://github.com/oobabooga/text-generation-webui.git cd text-generation-webui pip install -r requirements.txt Then, run the UI:
python server.py --model deepseek-ai/deepseek-coder-6.7B --device mpsNow, open https://localhost:5000 in a browser to interact with DeepSeek.
This command starts a Python server that runs DeepSeek-Coder 6.7B for inference.
python server.py: Runs the scriptserver.py, which likely starts an API or inference server.--model deepseek-ai/deepseek-coder-6.7B: Specifies the DeepSeek-Coder 6.7B model for processing requests.--device mps: Runs the model on Apple Silicon’s MPS for hardware acceleration.
This setup allows serving AI-generated responses via an API or local interface.
Installing DeepSeek Locally on a PC (Windows/Linux) With GUI
Windows challenges, include:
- Windows does not support vLLM natively.
- Best performance requires CUDA (NVIDIA GPUs) and WSL (Windows Subsystem for Linux).
Step 1: Install WSL (Windows Users)
For Windows users, install WSL 2 with Ubuntu:
wsl --installThe command wsl --install is used on Windows to install the Windows Subsystem for Linux (WSL), which allows running a Linux environment directly inside Windows.
- Enables WSL: Installs the necessary components for running Linux on Windows.
- Installs Ubuntu by Default: Downloads and installs the latest Ubuntu distribution unless another distro is specified.
- Simplifies Setup: Eliminates the need for manual configurations.
After installation, you can open a Linux terminal by running: wsl.
Then, open Ubuntu Terminal and update the system:
sudo apt update && sudo apt upgrade -yStep 2: Install NVIDIA CUDA & Python
If you have an NVIDIA GPU, install CUDA:
sudo apt install -y nvidia-cuda-toolkitThen, install Python:
sudo apt install python3 python3-venv python3-pipStep 3: Set Up Virtual Environment
python3 -m venv deepseek_env source deepseek_env/bin/activate pip install --upgrade pipStep 4: Install DeepSeek Model and vLLM
For NVIDIA GPUs:
pip install vllm torch transformers accelerateThis command installs several Python packages using pip, a package manager for Python. Here’s what each part does:
pip install: Installs Python libraries.vllm: A high-performance inference engine for running large language models efficiently.torch: The core PyTorch library, used for deep learning and neural network computations.transformers: A library from Hugging Face for working with pre-trained models like GPT and DeepSeek.accelerate: Optimizes deep learning model execution, enabling efficient multi-GPU and mixed precision training.
This command ensures you have all the necessary tools for running AI models efficiently.
For CPU-only users:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpuThe command installs PyTorch and its related libraries optimized for CPU-only systems.
Then, install DeepSeek:
pip install deepseek-aiStep 5: Run DeepSeek Model
from transformers import AutoModelForCausalLM, AutoTokenizer import torch model_id = "deepseek-ai/deepseek-coder-6.7B" device = "cuda" if torch.cuda.is_available() else "cpu" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained(model_id).to(device) prompt = "Explain the theory of relativity in simple terms." inputs = tokenizer(prompt, return_tensors="pt").to(device) outputs = model.generate(**inputs, max_length=100) print(tokenizer.decode(outputs[0], skip_special_tokens=True)) This Python script loads and runs DeepSeek-Coder 6.7B, an AI model for text generation. Here’s a breakdown:
1. Imports Necessary Libraries
transformers: Handles model and tokenizer loading.torch: Used for tensor computation and hardware acceleration.
2. Sets Up Model and Device
model_id: Specifies the DeepSeek-Coder model.device: Uses Apple Silicon’s MPS if available, otherwise defaults to CPU.
3. Loads Tokenizer & Model
- The tokenizer converts text into a format the model understands.
- The model is loaded onto the specified device.
4. Processes Input & Generates Output
- The input prompt
“Explain the theory of relativity in simple terms.”is tokenized. - The model generates text based on the input.
5. Decodes and Prints Output
- The output is converted from tokens back to human-readable text and displayed.
- This script allows text-based AI inference on local hardware, making it useful for code completion, content generation, and more
Step 6: Install a GUI Interface
Option 1: Text Generation Web UI
Install the web UI:
git clone https://github.com/oobabooga/text-generation-webui.git cd text-generation-webui pip install -r requirements.txtThen, start the UI:
python server.py --model deepseek-ai/deepseek-coder-6.7B --device cudaThis command starts a Python server that runs DeepSeek-Coder 6.7B for inference.
python server.py: Runs the scriptserver.py, which likely starts an API or inference server.--model deepseek-ai/deepseek-coder-6.7B: Specifies the DeepSeek-Coder 6.7B model for processing requests.--device cuda: Runs the model on NVDIA GPU for hardware acceleration.
This setup allows serving AI-generated responses via an API or local interface. Access it at https://localhost:5000.
Option 2: LM Studio (Windows & Mac)
For a more user-friendly experience, install LM Studio:
- Download and install LM Studio.
- Load DeepSeek models from Hugging Face.
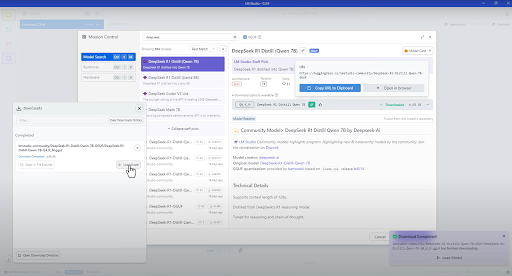
- Use the graphical interface to chat with the model.
Best Practices for Efficient DeepSeek Deployment
1. Fine-Tuning DeepSeek for Your Use Case
Fine-tuning DeepSeek on domain-specific datasets enhances accuracy and efficiency:
from transformers import Trainer, TrainingArguments trainer = Trainer(model, args=TrainingArguments(output_dir="./fine-tuned")) trainer.train()This improves efficiency in several ways:
- Handles model training, evaluation, and logging without manually writing loops.
- Automatically manages GPU/CPU execution, ensuring optimal resource usage.
- Uses mixed precision training (if enabled) to reduce memory consumption.
- Supports multi-GPU and distributed training for faster execution.
- Checkpoints the model in
output_dir, avoiding re-training from scratch. - Logs loss values, gradients, and performance metrics for monitoring.
2. Batch Processing to Improve Throughput
Instead of processing one request at a time, batch inputs together:
batch = torch.stack([input1, input2, input3]) output = model(batch)This improves efficiency in the following ways:
- Instead of processing each input separately, it combines multiple inputs into a single batch, reducing the number of forward passes required.
- Using batch processing allows GPUs to operate at higher efficiency, leveraging parallel computation.
- Fewer function calls and less memory allocation overhead compared to looping over individual inputs.
3. Deploying DeepSeek with Inference Servers
Using TorchServe or FastAPI ensures efficient model serving:
pip install torchserve torch-model-archiverDefine a model handler and serve it:
torchserve --start --model-store --models deepseek.marThis improves efficiency in the following ways:
torchserveturns a trained model into a web-accessible API, allowing multiple requests to be handled simultaneously.- Keeps the model loaded in memory, avoiding repeated initialization overhead.
- Optimizes throughput by handling multiple queries at once.
4. Profiling and Monitoring Performance
Use NVIDIA Nsight Systems to analyze performance bottlenecks:
nsys profile python run_deepseek.pyThis improves efficiency by profiling and analyzing DeepSeek’s execution performance using NVIDIA Nsight Systems (nsys). Here’s how:
- Captures detailed profiling data, highlighting slow operations in CPU, GPU, and memory usage.
- Helps detect inefficient kernel launches, improving deep learning inference/training efficiency.
- Identifies unnecessary computations or memory bottlenecks, leading to faster execution.
Troubleshooting Common Issues With DeepSeek Implementation
1. CUDA Out of Memory Errors
- Reduce batch size.
- Enable gradient checkpointing.
- Use
torch.cuda.empty_cache().
2. Slow Inference Performance
- Convert model to TorchScript for optimized inference:
scripted_model = torch.jit.script(model)- Use ONNX Runtime to accelerate inference:
pip install onnxruntime
More on AIDeep Convolutional Neural Networks (DCNN) Explained
Which Setup is Best for You?
- Mac (Apple Silicon): Use MPS with vLLM and Text Generation Web UI or LM Studio.
- Mac (Intel): Use CPU inference (slow) or run in a Docker Linux environment.
- PC (Windows NVIDIA GPU): Use WSL, CUDA and vLLM for best performance.
- PC (Windows CPU-only): Use LM Studio or CPU-based PyTorch
- PC (Linux NVIDIA GPU): Use CUDA and vLLM for maximum speed.

Deploying DeepSeek on a local machine gives professionals more flexibility, privacy, and customization compared to cloud-based solutions. However, choosing the right hardware, configuring dependencies, and optimizing system performance are key to unlocking its full potential. By leveraging GPU acceleration, memory-efficient techniques, and fine-tuning methods, DeepSeek can be efficiently deployed for a range of AI applications. Few notes to keep in mind at the end
- Running DeepSeek locally is resource-intensive.
- For best performance, use an NVIDIA GPU with CUDA.
- If running on a Mac, MPS is the best alternative to CUDA, but performance will be slower.
- GUI options like LM Studio or Text Generation Web UI make interaction easier.
Related Posts