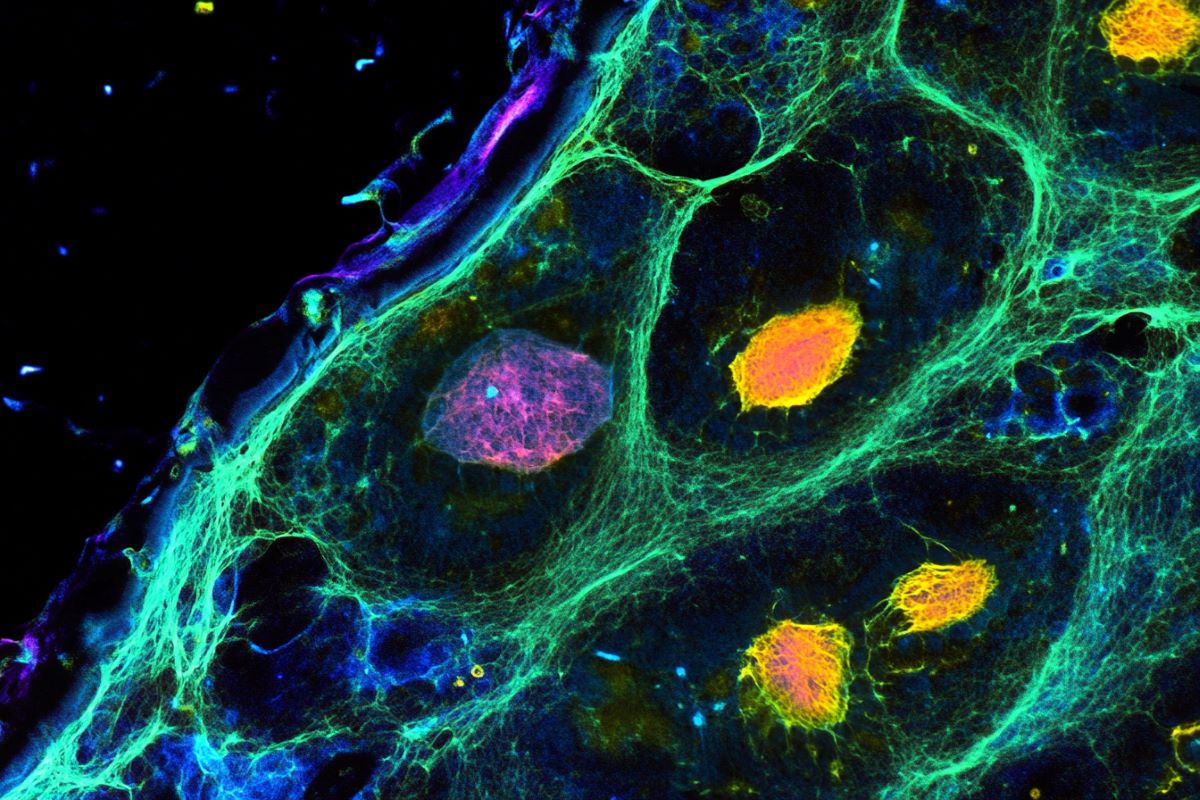
Summary: A study reveals how brain cell interactions influence aging, showing that rare cell types either accelerate or slow brain aging. Neural stem cells provide a rejuvenating effect on neighboring cells, while T cells drive aging through inflammation. Researchers used advanced AI tools and a spatial single-cell atlas to map cellular interactions across the lifespan

IBM Granite 3.1: powerful performance, longer context and more
Author
Kate Soule
Program Director, Data and Model Factory, IBM
Here’s the key info, at a glance:
- Granite 3.1 8B Instruct delivers significant performance improvements over Granite 3.0 8B Instruct. Its average score across the Hugging Face OpenLLM Leaderboard benchmarks is now among the highest of any open model in its weight class.
- We’ve expanded the context windows of the entire Granite 3 language model family. Our latest dense models (Granite 3.1 8B, Granite 3.1 2B), MoE models (Granite 3.1 3B-A800M, Granite 3.1 1B-A400M) and guardrail models (Granite Guardian 3.1 8B, Granite Guardian 3.1 2B) all feature a 128K token context length.
- We’re releasing a family of all-new embedding models. The new retrieval-optimized Granite Embedding models are offered in four sizes, ranging from 30M–278M parameters. Like their generative counterparts, they offer multilingual support across 12 different languages: English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch and Chinese.
- Granite Guardian 3.1 8B and 2B feature a new function calling hallucination detection capability, allowing increased control over and observability for agents making tool calls.
- All Granite 3.1, Granite Guardian 3.1, and Granite Embedding models are open source under Apache 2.0 license.
- These latest entries in the Granite series follow IBM’s recent launch of Docling (an open source framework for prepping documents for RAG and other generative AI applications) and Bee (an open source, model agnostic framework for agentic AI).
- Granite TTM (TinyTimeMixers), IBM’s series of compact but highly performant timeseries models, are now available in watsonx.ai through the beta release of watsonx.ai Timeseries Forecasting API and SDK.
- Granite 3.1 models are now available in IBM watsonx.ai, as well as through platform partners including (in alphabetical order) Docker, Hugging Face, LM Studio, Ollama and Replicate.
- Granite 3.1 will also be leveraged internally by enterprise partners: Samsung is integrating select Granite models into its SDS platform; Lockheed Martin is integrating Granite 3.1 models into its AI Factory tools, used by over 10,000 developers and engineers.
Today marks the release of IBM Granite 3.1, the latest update to our Granite series of open, performant, enterprise-optimized language models. This suite of improvements, additions and new capabilities focuses primarily on augmenting performance, accuracy and accountability in essential enterprise use cases like tool use, retrieval augmented generation (RAG) and scalable agentic AI workflows.
Granite 3.1 builds upon the momentum of the recently launched Granite 3.0 collection. IBM will continue to release updated models and functionality for the Granite 3 series in the coming months, with new multimodal capabilities slated for release in Q1 2025.
These new Granite models are not the only notable recent IBM contributions to the open source LLM ecosystem. Today’s release caps off a recent run of innovative open source launches, from a flexible framework for developing AI agents to an intuitive toolkit to unlock essential information stashed away in PDFs, slide decks and other file formats that are difficult for models to digest. Using these tools and frameworks in tandem with Granite 3.1 models offers developers evolved capabilities for RAG, AI agents and other LLM-based workflows.
As always, IBM’s historical commitment to open source is reflected in the permissive and standard open source licensing for every offering discussed in this article.
Granite 3.1 8B Instruct: raising the bar for lightweight enterprise models
IBM’s efforts in the ongoing optimization the Granite series are most evident in the growth of its flagship 8B dense model. IBM 3.1 Granite 8B Instruct now bests most open models in its weight class in average scores on the academic benchmarks evaluations included in the Hugging Face OpenLLM Leaderboard.
The evolution of the Granite model series has continued to prioritize excellence and efficiency in enterprise use cases, including agentic AI. This progress is most apparent in the newest 8B model’s significantly improved performance on IFEval, a dataset featuring tasks that test a model’s ability to follow detailed instructions, and Multi-step Soft Reasoning (MuSR), whose tasks measure reasoning and understanding on and of long texts.
Expanded context length
Bolstering the performance leap from Granite 3.0 to Granite 3.1 is the expansion of all models’ context windows. Granite 3.1’s 128K token context length is on par with that of other leading open model series, including Llama 3.1–3.3 and Qwen2.5.
The context window (or context length) of a large language model (LLM) is the amount of text, in tokens, that an LLM can consider at any one time. A larger context window enables a model to process larger inputs, carry out longer continuous exchanges and incorporate more information into each output. Tokenization doesn’t entail any fixed token-to-word “exchange rate,” but 1.5 tokens per word is a useful estimate. 128K tokens is roughly equivalent to a 300-page book.
Above a threshold of about 100K tokens, impressive new possibilities emerge, including multi-document question answering, repository-level code understanding, self-reflection and LLM-powered autonomous agents.1 Granite 3.1’s expanded context length thus lends itself to a much wider range of enterprise use cases, from processing code bases and lengthy legal documents in their entirety to simultaneously reviewing thousands of financial transactions.
Granite Guardian 3.1: detecting hallucinations in agentic workflows
Granite Guardian 3.1 8B and Granite Guardian 3.1 2B can now detect hallucinations that might occur in an agentic workflow, affording the same accountability and trust to function calling that we already provide for RAG.
Many steps and subprocesses occur in the space between the initial request sent to an AI agent and the output the agent eventually returns to the user. To provide oversight throughout, Granite Guardian 3.1 models monitor every function call for syntactic and semantic hallucinations.
For instance, if an AI agent purportedly queries an external information source, Granite Guardian 3.1 monitors for fabricated information flows. If an agentic workflow entails intermediate calculations using figures retrieved from a bank record, Granite Guardian 3.1 checks to see whether the agent pulled the correct function call along with the appropriate numbers.
Today’s release is yet another step toward accountability and trust for any component of an LLM-based enterprise workflow. The new Granite Guardian 3.1 models are available on Hugging Face. They’ll also be available through Ollama later this month and on IBM watsonx.ai in January 2025.
Granite embedding models
Embeddings are an integral part of the LLM ecosystem. An accurate and efficient means of representing words, queries and documents in numerical form is essential to an array of enterprise tasks including semantic search, vector search and RAG, as well as maintaining effective vector databases. An effective embedding model can significantly enhance a system’s understanding of user intent and increase the relevance of information and sources in response to a query.
While the past two years have seen the proliferation of increasingly competitive open source autoregressive LLMs for tasks like text generation and summarization, open source embedding model releases from major providers are relatively few and far between.
The new Granite Embedding models are an enhanced evolution of the Slate family of encoder-only, RoBERTA-based language models. Trained with the same care and consideration for filtering bias, hate, abuse and profanity (“HAP”) as the rest of the Granite series, Granite Embedding is offered in four model sizes, two of which support multilingual embedding across 12 natural languages:
- Granite-Embedding-30M-English
- Granite-Embedding-125M-English
- Granite-Embedding-107M-Multilingual
- Granite-Embedding-278M-Multilingual
Whereas the vast majority of open embedding models on the Hugging Face MTEB leaderboard rely on training datasets licensed only for research purposes, such as MS-MARCO, IBM verified the commercial eligibility of all data sources used to train Granite Embedding. Underscoring the care taken to support enterprise use, IBM supports Granite Embedding with the same uncapped indemnity for third party IP claims provided for use of other IBM-developed models.
IBM’s diligence in curating and filtering training data did not prevent the English Granite Embedding models from keeping pace with prominent similarly sized open source embedding models in internal performance evaluations conducted using the BEIR evaluation framework.
IBM testing also demonstrated that two of the new embedding models, Granite-Embedding-30M-English and Granite-Embedding-107M-Mulilingual, significantly exceed rival offerings in terms of inference speed.
This launch initiates IBM Research’s ambitious roadmap for continued innovation with the open source Granite Embedding model family. Updates and upgrades planned for 2025 include context extension, optimization for RAG and multimodal retrieval capabilities.
Document deciphering and agentic AI
Alongside the ongoing evolution of the Granite series, IBM is continuing its firm commitment to open source AI through the recent development and open source release of innovative new tools and frameworks for building with LLMs. Optimized for Granite models but inherently open and model agnostic, these IBM-built resources help developers harness the full potential of LLMs, from facilitating fine-tuning pipelines to regularizing RAG sources to assembling autonomous AI agents.
Docling: prep documents for RAG, pretraining and fine-tuning
From creative writing to RAG, generative AI is ultimately an engine that runs on data. The true potential of large language models can’t be realized if some of that data is trapped in formats that models can’t recognize. LLMs are fairly new, but the problem is not: as a decade-old Washington Post headline proclaimed, “the solutions to all our problems may be buried in PDFs that nobody reads.”
That’s why IBM Deep Search developed Docling, a powerful tool for parsing documents in popular formats including PDF, DOCX, images, PPTX, XLSX, HTML and AsciiDoc and converting them into model-friendly formats like Markdown or JSON. This enables those documents—and the information therein—to be easily accessed by models like Granite for the purposes of RAG and other workflows. Docling allows for easy integration with agentic frameworks such as LlamaIndex, LangChain and Bee, enabling developers to incorporate its assistance into their ecosystem of choice.
Open sourced under the permissive MIT License, Docling is sophisticated solution that goes beyond simple optical character recognition (OCR) and text extraction. As William Caban at Red Hat explains, Docling integrates a number of contextual and element-based preprocessing techniques: if a table spans multiple pages, Docling knows to extract it as a single table; if a given page mixes body text, images and tables, each must be extracted separate in accordance with their original context.
The team behind Docling is actively working on additional features, including equation and code extraction and metadata extraction. To see Docling in action, check out this tutorial for building a document question answering system with Docling and Granite.
Bee: agentic AI framework for open models
The Bee Agent Framework is an open source framework for building powerful agentic AI workflows with open source LLMs, optimized for use with Granite and Llama models (with further model-specific optimizations already in development). It includes an array of modules that allow developers to customize almost any component of the AI agent, from memory handling to tool use to error handling, as well as multiple observability features that provide the insights and accountability necessary for production deployment.
The framework seamlessly integrates with multiple models and a suite of robust ready-to-use tools like weather services and internet search (or custom tools authored in Javascript or Python). Bee’s flexible tool use functionality enables workflows tailored to your specific circumstances, as demonstrated in this recipe using Granite and Wikipedia that leverages built-in tools to more effectively utilize a limited context window.
Granite Bee agents can be run locally using Ollama or leverage hosted inference with watsonx.ai.
Timeseries forecasting in IBM watsonx.ai
Released earlier this year, Granite’s TinyTimeMixer (TTM) timeseries models are a family of pre-trained, lightweight models based on a novel architecture. Tackling zero-shot and few-shot forecasting for anything from IoT sensor data to stock market prices and energy demands, Granite Timeseries models outperform many models that are up to 10 times their size, including TimesFM, Moirai and Chronos.2 Since May 30, Granite-timeseries-TTM models have been downloaded over 3.25 million times on Hugging Face alone.
In November, IBM announced the beta launch of the watsonx.ai Timeseries Forecasting API and SDK, making Granite timeseries models available on IBM’s integrated AI platform for end-to-end AI application development.
For more information on getting started with Granite-TTM, check out the recipes in the IBM Granite Timeseries cookbook, such as this notebook for using the watsonx SDK to perform forecasting inference.
Getting started with Granite 3.1
Granite 3.1 models are now available on IBM watsonx.ai. They can also be accessed through platform partners including—alphabetically—Docker (through its DockerHub GenAI catalog), Hugging Face, LM Studio, Ollama and Replicate. Select Granite 3.1 models will also be available through NVIDIA (as NIM Microservices) in January 2025.
A number of guides and recipes for working with Granite models are available in the Granite Snack Cookbook on GitHub, from orchestrating workflows using Granite language models in Langchain to implementing Granite Guardian models.
Developers can also get started with Granite models in the Granite model playground or by exploring the array of useful demos and tutorials in IBM docs, such as:
- Building a document question answering system with Docling and Granite
- Implementing agentic RAG locally with Ollama, Open WebUI and Granite 3.1
Explore the Granite 3.1 models →
Learn more about IBM’s open, state-of-the-art enterprise LLMs.
See for yourself: prompt the new Granite 3.1 models in Granite Playground.
Related Posts