Just_Super via Getty Images By Kaitlyn Levinson,Reporter, Route Fifty By Kaitlyn Levinson | June 3, 2026 04:19 PM ET Through adequate AI training and keeping humans in the loop of AI-driven solutions, governments can harness the technology to address increasing cyber threats to the public sector, speakers said during a recent event. Artificial intelligence Cybersecurity
Multi-omics and artificial intelligence for precision drug discovery and potential clinical applications – Signal Transduction and Targeted Therapy
Introduction
Contemporary pharmaceutical development persists as an exceptionally high-risk venture characterized by clinical trial attrition rates that now exceed 90% and aggregate expenditures that have risen to an average of 2.6 billion USD for every therapeutic that ultimately secures marketing approval.1 These staggering metrics reflect more than escalating expenses in labor, materials, and regulatory compliance; they reveal a profound epistemological limitation embedded in the prevailing reductionist models of disease pathogenesis. The traditional “one-drug-one-target” paradigm—despite historic successes in treating conditions such as infectious diseases and hypertension—fails to account for the intricate molecular interplay across genomic, epigenomic, transcriptomic, proteomic, and metabolomic domains. In malignancies, for example, a single oncogenic driver mutation can reconfigure signaling cascades, reshape transcriptional landscapes, and reprogram metabolic fluxes within the tumor microenvironment—dynamics that defy correction through isolated molecular inhibition. Comparable multiomic dysregulation characterizes autoimmune and neurodegenerative diseases, where protein misfolding, chronic inflammation, and metabolic dysfunction interact in self-perpetuating feedback loops.2 The translational pipeline is further constrained by the continued inadequacy of preclinical models. Standard immortalized cell lines grown on rigid two-dimensional substrates fail to mimic the three-dimensional architecture, extracellular matrix variability, and immune contexture intrinsic to human pathology. Genetically engineered mouse models, while instrumental for mechanistic studies, rarely capture the polygenic complexity or environmental heterogeneity that defines human disease susceptibility. Even advanced systems such as microphysiological platforms and patient-derived organoids struggle to emulate systemic endocrine regulation or the longitudinal clonal evolution characteristics of human tumors. As a result, therapeutic candidates that perform well in these simplified contexts frequently underperform in clinical trials, contributing to a costly translational bottleneck that hinders therapeutic innovation and delays patient access to critical treatments. To address this impasse, the field is increasingly embracing integrative approaches that fuse high-resolution multiomic data with machine learning (ML)-driven inference of causal network perturbations. When iteratively tested in dynamic, human-relevant models—including longitudinal organoid biobanks, immune-humanized mouse systems, and in silico digital twins—these frameworks offer the potential to disentangle complex disease etiologies and accelerate the translation of mechanistic insight into clinically actionable interventions.3
The emergence of multiomics analytical platforms offers an unprecedented systems-level lens on biological complexity by integrating genomics, epigenomics, transcriptomics, proteomics, and metabolomics into unified, multidimensional datasets that comprehensively capture molecular states within individual biological specimens. Enabled by cloud-scale computational frameworks and AI-driven data harmonization, these integrative pipelines eliminate the fragmentation once imposed by siloed methodologies, facilitating seamless traversal from single-nucleotide variants to organism-level phenotypes. Within this paradigm, spatial transcriptomics—exemplified by multiplexed error-robust fluorescence in situ hybridization (MERFISH), 10x Genomics Visium, and emerging in situ sequencing chemistries—precisely charts gene expression gradients and cellular microenvironments within intact tissue architecture at subcellular resolution. By retaining spatial coordinates, these technologies elucidate how ligand‒receptor signaling networks, metabolic zonation, and biomechanical forces coevolve to shape tumor‒immune interactions. MERFISH, for example, can simultaneously quantify hundreds of immune checkpoint transcripts in individual CD8 + T cells while measuring their spatial proximity to PD-L1+ macrophages, thereby identifying immune-excluded microanatomical niches predictive of resistance to checkpoint blockade. Visium extends this analysis by superimposing expression profiles onto hematoxylin- and eosin-stained histological features, enabling ML-based integration of morphological and transcriptomic information to identify spatially resolved biomarkers for clinical stratification. These spatial omics technologies collectively transform static tissue samples into high-dimensional atlases that illuminate the spatiotemporal choreography of disease evolution and therapeutic response.4 Concurrently, single-cell sequencing modalities—including single-cell RNA sequencing (scRNA-seq), scATAC–seq, and integrated multimodal derivatives—offer nucleotide-resolution insights into clonal hierarchies, transcriptional dynamics, and epigenetic plasticity within neoplastic and inflammatory contexts. scRNA-seq, through full-length or 3′-tagged mRNA capture across thousands of individual cells, delineates oncogenic trajectories, stem-like programs, and stress-adaptive modules across molecularly distinct yet spatially colocalized subpopulations while quantifying intercellular communication via ligand‒receptor interactions spanning malignant, stromal, and immune compartments. scATAC-seq, applied to the same cellular populations, generates genome-wide chromatin accessibility maps that reveal lineage-specific enhancer activity, transcription factor binding dynamics, and regulatory plasticity that modulate therapeutic sensitivity. Joint profiling platforms such as SHARE-seq and 10x Multiome further align chromatin landscapes with matched transcriptomes, enabling high-resolution inference of cis-regulatory logic and enhancer‒gene interactions at true single-cell fidelity. Advanced computational frameworks—leveraging mutual nearest-neighbor anchoring, RNA velocity mapping, and lineage reconstruction algorithms—reconstruct pseudotemporal trajectories that trace the progression from premalignant founder clones through subclonal diversification, delineating how mutational load, structural genomic alterations, and microenvironmental inputs collectively drive transcriptional and epigenetic heterogeneity. In immune-mediated disease, similar analyses map differentiation trajectories from naïve T-cell activation to exhaustion or tissue residency while concurrently identifying enhancer remodeling events that entrench pathogenic cytokine expression. Together, these single-cell multiomic platforms generate high-resolution, temporally dynamic maps of intratumoral and intralesional heterogeneity, informing rational combination strategies that disrupt adaptive resistance mechanisms and reestablish effective immune surveillance.5 High-throughput proteomic technologies—including mass spectrometry and affinity-based arrays—enable the identification of disease-associated posttranslational modifications (e.g., phosphorylation, ubiquitination) and aberrant signaling cascades, whereas metabolomic flux analysis quantifies dynamic perturbations in biochemical pathways.6 Synergistic integration of these multidimensional datasets with artificial intelligence—leveraging deep neural networks (DNNs) for pattern recognition, graph neural networks (GNNs) for biological network inference, and transformers for multimodal data fusion—empowers the computational deconvolution of pathobiological mechanisms and the discovery of therapeutically tractable vulnerabilities invisible to reductionist methodologies. Illustratively, AI-driven structural biology platforms (e.g., AlphaFold, RoseTTAFold) achieve near-experimental accuracy in protein folding prediction, whereas generative adversarial networks (GANs) and reinforcement learning enable the de novo design of compounds with tailored pharmacokinetic/pharmacodynamic profiles.
This convergence of multiomics and AI fundamentally reconfigures drug discovery through three pivotal shifts: (1) transitioning from monotarget inhibition to network pharmacology models targeting disease-perturbed interactomes7,8,9; (2) replacing linear, sequential development with parallelized, adaptive cycles that iteratively integrate computational predictions and experimental validation10; and (3) evolving beyond population-based therapies toward patient-specific digital twin simulations integrating individual multiomics profiles for treatment optimization.11 Emerging clinical implementations signal the transformative potential of this framework. For example, AI-designed SOMAmer therapeutics targeting the plasma proteome have reduced development time to phase II trials by 60% relative to conventional benchmarks.12 Nonetheless, substantive translational barriers remain due to persistent heterogeneity in data acquisition protocols, analytical pipelines, and ontological frameworks across public repositories (e.g., GEO, TCGA, PRIDE), which compromises the reliability of cross-study meta-analyses.13 In particular, inconsistent data standardization further obstructs effective integration across studies.14 The inherently static nature of current multiomics measurements limits temporal resolution, constraining efforts to model dynamic disease trajectories and mechanisms of adaptive resistance. Ethical and technical challenges further complicate deployment: the opacity of high-complexity AI models undermines interpretability; algorithmic biases threaten to amplify healthcare inequities; and the high cost of precision platforms raises concerns regarding equitable global access.
This review provides a comprehensive analysis of multiomics integration throughout the drug development pipeline, encompassing target identification, drug repurposing, and de novo compound generation. It also delineates the expanding role of AI in domains such as virtual screening, PK modeling, and toxicity prediction. Emphasis is placed on the synergistic interplay between multiomics and AI, with case studies in oncology, neurology, and cardiovascular disease (CVD) that illustrate translational impact. By synthesizing current opportunities and persistent limitations, this work outlines a strategic roadmap for advancing next-generation therapeutic discovery.
Literature-search strategy
This systematic literature review aims to comprehensively consolidate scholarly resources relevant to the intersection of multiomics and artificial intelligence in precision drug discovery. The included materials include peer-reviewed journal articles, conference proceedings, and other academically rigorous sources. The objective is to delineate the current research landscape, trace its historical evolution, identify dominant conceptual frameworks, evaluate methodological innovations, highlight ongoing debates, and map emerging trajectories—thereby establishing a solid evidentiary basis for the development of a critical review. Electronic searches were conducted across PubMed, Web of Science, and Scopus, guided by thematically tailored query strategies for each review section. Controlled vocabulary expansion, including Medical Subject Headings (MeSH), was employed to increase retrieval sensitivity. Structured Boolean logic was applied to balance recall and specificity, with key constructs combined via the AND operator to ensure contextual relevance (e.g., [Multi-Omics] AND [Drug Discovery]). This multiplatform, synonym-expanded, and rigorously structured search protocol guarantees comprehensive and reproducible identification of literature essential to advancing integrative frameworks for AI-enabled, multiomics-driven drug discovery.
Multi-omics in drug discovery
In contemporary pharmaceutical R&D, the systematic integration of multiomics data has transitioned from exploratory research to an indispensable paradigm for holistic systems biology interrogation and therapeutic target identification.15,16,17 While methodologically informative, traditional single-omics strategies often fall short in capturing the complex interplay among genomic drivers, transcriptional regulators, proteomic effectors, and metabolic intermediates that collectively define pathophysiological states.18,19,20,21 Integrated multiomics methods (including genomics, epigenomics, transcriptomics, proteomics, metabolomics, and microbiomics) can effectively circumvent this problem. Recent breakthroughs in high-resolution omics technologies—such as single-cell sequencing, spatial proteomics, and real-time metabolomics—combined with advanced computational infrastructures, including graph-based data models and tensor decomposition techniques, have significantly expanded the analytical bandwidth for integrative multiomics fusion.
ML has emerged as a pivotal enabler in this domain. Ensemble algorithms (e.g., random forest [RF], XGBoost) support robust feature selection, whereas deep learning (DL) models (e.g., autoencoders, transformers) uncover latent structures across omics layers, revealing nonlinear dependencies and emergent properties that are often inaccessible through reductionist methodologies. Notably, active learning frameworks leveraging human-AI interactions have shown marked success in target prioritization pipelines by integrating disease-specific multiomics signatures with functional validation evidence.14 The proliferation of cloud-native multiomics platforms (e.g., BioVLAB, Seven Bridges) further democratizes access to scalable, containerized workflows, allowing research groups with limited computational infrastructure to conduct end-to-end systems pharmacology analyses.22 Despite these advancements, several methodological challenges remain unresolved: harmonizing data across disparate platforms and batches, ensuring algorithmic resilience to incomplete omics profiles, inferring causality from observational data, and achieving reproducible analyses across diverse computational environments. Nonetheless, multiomics integration is widely acknowledged as a foundational strategy for next-generation therapeutic discovery, with the potential to improve target validation fidelity and reduce late-stage clinical failure.
Application of multiomics in the identification of drug targets
The rapid advancement of multiomics profiling technologies over the past decade has profoundly redefined the methodological paradigm for therapeutic target discovery.23,24,25 By systematically integrating orthogonal molecular layers—encompassing whole-genome variation, single-cell transcriptomics, posttranslational proteomics, dynamic metabolomics, and epigenomic regulatory signatures—researchers are now equipped to resolve disease-altered interactomes with unprecedented granularity. This integrative systems biology strategy enables (1) computational reconstruction of pathological signaling cascades across hierarchical biological contexts; (2) identification of master regulatory nodes—such as pleiotropic kinases, epigenetic modifiers, and noncoding RNA hubs—via network centrality metrics; and (3) quantification of target tractability through assessments of druggability and functional essentiality.26,27
Emergent analytical approaches, particularly multimodal tensor decomposition and causal inference-based ML models, translate these high-dimensional datasets into mechanistically coherent target hypotheses. This framework has become instrumental in uncovering synthetic lethal gene pairs in oncology, modulatory switches in neurodegenerative disorders, and upstream drivers of immunometabolic inflammation—thus operationalizing molecular pathobiology into actionable therapeutic avenues. CRISPR-based gene-editing platforms have further catalyzed this transition by enabling the construction of genome-scale functional vulnerability atlases, delineating cell-type-specific genetic susceptibilities through systematic knockout screens in disease-relevant cellular models.28,29,30 These molecular cartographies are critical for identifying high-risk cellular phenotypes, facilitating the design of precision prevention strategies, and optimizing translational workflows within resource-constrained environments. Integration of next-generation sequencing with multiplexed CRISPR-guided RNA libraries has scaled functional genomics into massively parallel screening campaigns, exemplified by initiatives such as the Cancer Dependency Map.31,32,33 These efforts have generated (1) comprehensive catalogs of context-specific essential genes; (2) mechanistic insights into synthetic lethal interactions; and (3) high-confidence therapeutic target nominations. The application of CRISPR-Cas9 screening to dissect drug resistance in non-small cell lung carcinoma has elucidated core functional dependencies within oncogenic networks, implicating targets such as EGFR (epidermal growth factor receptor), KRAS (Kirsten rat sarcoma viral oncogene homolog), TP53 (tumor protein p53), and antiapoptotic regulators such as BCL2 (B-cell lymphoma 2) as clinically actionable vulnerabilities. Notably, phenotypic CRISPR interrogation in advanced three-dimensional tumor microphysiological systems—including patient-derived organoids and matrix-embedded spheroids—enhances translational relevance by recapitulating critical in vivo features such as hypoxic gradients, biomechanical forces, and stromal–epithelial interactions.34,35,36 This methodology recently revealed that carboxypeptidase D enzymatically cleaves the C-terminal RKRR motif of the IGF1R α-subunit, a posttranslational modification essential for autophosphorylation and downstream signaling fidelity. Functional CRISPR ablation of carboxypeptidase D in glioblastoma models significantly attenuated IGF1R-mediated PI3K/AKT/mTOR pathway activation, suppressed tumor-initiating cell expansion, and impaired xenograft tumorigenicity37—thereby establishing this protease as both a mechanistic effector of oncogenic signaling and a promising therapeutic target in solid tumors. Like architectural blueprints fail to capture the operational vulnerabilities of a building, single-dimensional genetic data offer limited insight into cellular fragility. Advances in systems biology have facilitated the integration of multiomics datasets—encompassing genomic, transcriptomic, and proteomic profiles—to construct more comprehensive “strategic maps” of disease processes.37,38 In a landmark study, Pacini et al. developed the second-generation cancer dependency map (DepMap 2.0) by concurrently profiling the genomic landscape (“genetic identity”), transcriptome (“work log”), proteome (“social network”), and clinical annotations (“medical history”) of 930 cancer cell lines.22 These multidimensional nodes frequently serve as critical regulators in oncogenic progression. Consequently, integrative analysis has become indispensable for elucidating disease mechanisms and generating insights beyond the reach of conventional methodologies. For example, Wang et al. performed a systems-level investigation of chronic obstructive pulmonary disease (COPD) by integrating genomic, transcriptomic, proteomic, and metabolomic data. Through the use of bioinformatic approaches for drug target prediction, they identified SPP1 (Secreted Phosphoprotein 1) and APOA1 (Apolipoprotein A1) as promising therapeutic candidates for COPD intervention.39 While canonical paradigms suggest that inhibiting oncogenic drivers such as KRAS and EGFR triggers cancer apoptosis,40 recent findings indicate a more nuanced landscape. Over half of cancer cell fatalities arise from “acquired addiction”—a state in which cells become reliant on hyperactivated genes for continued survival.41 This dependency resembles substance addiction, where withdrawal from an overstimulated condition leads to systemic collapse. Additionally, research has revealed synergistic gene modules that jointly regulate processes such as DNA replication and bioenergetics to drive cell cycle acceleration,42,43 along with metabolic circuits that sustain tumor viability under hypoxic stress. The relationship between gene expression and protein modification offers insights into how genetic alterations influence protein function, potentially identifying therapeutic targets. Protein interaction network analysis has shown that non-oncogenic genes are often vulnerable due to their critical roles at “social nodes” within these networks. For example, although the FGFR protein family is not a driver in breast cancer, its position in connecting multiple signaling pathways makes it a strategic target. Inhibiting FGFR can disrupt the entire network.44 Multiomics data, encompassing genes, transcription, proteins, and metabolites, provide robust evidence to validate target–disease associations, enhancing the reliability of the validation process. By monitoring changes in gene expression, protein modifications, and metabolite levels, the role of potential targets in disease progression can be elucidated.45,46 For example, Liang et al. integrated RNA-seq, proteomics, and other techniques to analyze the cellular origins of bone factors and the interorgan communications they facilitate (e.g., bone‒brain and liver‒aorta interactions). This study identified 375 candidate bone factors and mapped a dynamic regulatory network, offering insights into their potential as drug targets.47 Understanding dynamic shifts in both physiological and pathological contexts is crucial for drug target discovery.46,48 Multiomics enables the construction of a comprehensive, multifaceted view of disease dynamics, with additional examples presented in Table 1.
Full size table
Contemporary drug discovery is increasingly focused on technological convergence and cross-scale system integration, with spatial multiomics emerging as a key paradigm for microenvironment-aware target identification. This approach maps molecular topographies at tumor-stroma interfaces through advanced techniques such as spatially resolved transcriptomics (e.g., Visium, MERFISH), multiplexed ion beam imaging (MIBI), and laser capture microdissection-coupled proteomics.49,50,51,52 For example, integrated spatial metabolomics-lipidomics using array-guided transcriptomic mass spectrometry (t-MSI) offers subcellular-resolution visualization of metabolic compartmentalization within gastric carcinoma samples, highlighting claudin-18+ tumor cell metabolic reprogramming at invasive fronts and quantifying phospholipid remodeling gradients across tumor–normal transition zones.53,54,55 These findings provide novel insights into the hierarchical organization of tumor ecosystems. In addition, single-cell multiomic profiling (e.g., scCOOL-seq, TEA-seq) addresses cellular heterogeneity by capturing epigenetic states, transcriptomic signatures, and surface proteomes within individual cells.50 This approach recently identified copper-dependent mitochondrial cell death (cuproptosis) as a pancarcinoma vulnerability axis, where FDX1high SLC31A1+ subpopulations exhibit selective sensitivity to copper ionophores.56 Furthermore, single-cell multiomics analysis of primary B-ALL cells revealed significant heterogeneity in response to asparaginase treatment. Huang et al. demonstrated that targeting BCL2, a key driver in the pre-B-like cell signaling network, with venetoclax significantly enhanced asparaginase efficacy both in vitro and in vivo. This single-cell pharmacological framework can thus predict optimal combination therapies tailored to internal heterogeneity across diverse disease states.26 The exploration of microbiome‒host interactions has introduced a transformative paradigm in therapeutic discovery. Metabolic enzymes from the gut microbiota and their bioactive metabolites, particularly short-chain fatty acids (SCFAs), exert significant modulatory effects on host signaling pathways through epigenetic mechanisms, suggesting promising therapeutic targets.57,58 The gut microbiota influences the expression of ten-eleven translocation methylcytosine dioxygenase 1 (TET1), thereby modulating DNA hydroxymethylation dynamics and orchestrating the epigenetic programming that governs innate lymphoid cell (ILC) differentiation, impacting ILC1 expansion and intestinal homeostasis.59 Butyrate, a key microbial SCFA, promotes the differentiation of regulatory B cells (Bregs; B10 phenotype) by inhibiting HDAC and activating p38 mitogen-activated protein kinase (MAPK). In gnotobiotic mouse models colonized with wild-type or mutant strains of butyrate-producing bacteria, Donohoe et al. demonstrated that dietary fiber exerts potent tumor-suppressive effects in a microbiota- and butyrate-dependent manner.60 Notably, this immunoregulatory pathway operates independently of G protein-coupled receptor signaling, highlighting the therapeutic potential of butyrate in ameliorating experimental colitis and arthritis.61 Owing to its programmable DNA editing capabilities, the CRISPR‒Cas system has revolutionized gene therapy and genetic engineering. Recent advancements, particularly the use of nuclease-inactive Cas enzymes, have enabled the development of diverse genetic engineering platforms. The combination of CRISPR activation (CRISPRa) and CRISPR interference (CRISPRi) systems with omics approaches facilitates large-scale functional genomics exploration.62,63 Integrating CRISPR-based approaches with multiomics, such as Perturb-seq, enables high-throughput screening of synthetic lethal targets, opening new avenues for combination therapies.64,65 Hou et al. employed a genome-wide CRISPR knockout screen integrated with multiomics analyses—spanning CRISPR screening datasets, GWAS, scRNA-Seq, and host-viral protein/RNA interactome data—to systematically identify proviral host factors for SARS-CoV-2.66 This approach revealed several underexplored host dependencies, notably components of the vacuolar-type ATPase (V-ATPase), endosomal sorting complex required for transport (ESCRT), and N-glycosylation pathways, which are critical for viral entry and/or replication. Validation experiments confirmed the antiviral efficacy of three high-priority targets: DAZAP2, VTA1, and KLF5. Concurrent studies have also linked genetic and epigenetic determinants to schizophrenia (SCZ) treatment outcomes.67,68,69,70 Large-scale population cohort analyses offer a robust framework for discovering clinically translatable targets.71,72,73 For example, Shi et al. integrated Mendelian randomization (MR) with multiomics datasets from nonischemic cardiomyopathy (NICM) individuals, identifying leukocyte immunoglobulin-like receptor subfamily A member 5 (LILRA5) and NELL1 as promising therapeutic targets, with expression data further supported by the Human Protein Atlas (HPA) and Comparative Toxicogenomics Database (CTD). Notably, LILRA5 has emerged as a promising target for diabetic cardiomyopathy.74
Despite the promising potential of multiomics in drug target discovery, several challenges remain. The integration of crossomics data requires the development of unified algorithmic frameworks, such as multiomics factor analysis, to address issues related to data heterogeneity and batch effects.
The application of multiomics in drug repurposing
The emergence of multiomics technology has revolutionized drug repurposing, providing a systematic and unparalleled approach that has accelerated the discovery of “old drugs for new uses” by deeply analyzing the complex interaction networks between disease molecular characteristics and existing drugs.75 Traditional repurposing strategies are often limited by the narrow scope of single-omics data, while multiomics integration—linking genome, proteome, and metabolome data—enables the systematic identification of hidden drug‒target‒pathway associations.16,76 By assessing the effects of drugs on gene expression, protein synthesis, and metabolite profiles, multiomics facilitates the precise identification of novel drug targets and action pathways (Table 2). For example, Li et al. developed a computational drug repositioning method, drug repositioning perturbation score/classification (DRPS/C), on the basis of proteomic and transcriptomic profiles. This approach identified voltage-gated sodium channel blockers (bupivacaine, topiramate) and monoamine oxidase inhibitors (selegiline, iproniazid) as promising candidates for Alzheimer’s disease (AD) treatment.77,78 In addition, in the context of COVID-19, transcriptomic screening revealed abnormal activation of the IL-6/JAK-STAT pathway, while protein interaction network predictions suggested the efficacy of anti-inflammatory drugs such as tocilizumab and the JAK inhibitor baricitinib. These predictions have been swiftly validated in clinical trials.79,80 In HIV-1 research, transcriptomic analysis of CD4 + T cells highlighted elevated oxidative phosphorylation (OXPHOS) pathways as markers of poor prognosis. Metformin, an FDA-approved drug that inhibits OXPHOS by targeting mitochondrial respiratory chain complex-1, was shown to inhibit HIV-1 replication in both human CD4 + T cells and humanized mice, positioning it as a potential HIV treatment.81 Furthermore, multiomics data contribute to the construction of intricate biological networks, including gene regulatory networks, protein interaction networks, and metabolic pathways. Multiomics-based “network pharmacology” frameworks—such as STITCH and DrugBank—quantify the multitarget effects of drugs, overcoming the limitations of the traditional “single-target-single-disease” paradigm.82,83,84 Yang et al. employed an integrative multiomics strategy—combining metabolomics, lipidomics, network pharmacology, and qPCR analysis—to comprehensively investigate the effects of Liupao tea extract (LPTE) on hepatic lipid metabolism. This approach identified naringenin, quercetin, luteolin, and kaempferol as the principal bioactive constituents of LPTE. Mechanistically, these compounds demonstrate therapeutic potential against nonalcoholic fatty liver disease (NAFLD) by targeting key proteins, including prostaglandin-endoperoxide synthase 2 (PTGS2), cytochrome P450 3A4 (CYP3A4), and acetylcholinesterase (ACHE), which regulate metabolic pathways involved in hepatic linoleic acid (LA) and glycerophospholipid (GP) metabolism.85 Similarly, Ye et al. utilized a convergent analytical framework, combining metabolomics, network pharmacology, and transcriptomics, to elucidate the therapeutic mechanisms of Dengzhan Shengmai capsule against ischemic stroke. This integrated approach revealed its potent antithrombotic activity and the efficacy of its active compounds (schisanhenol, apigenin, and gomisin B), providing a molecular foundation for its clinical use in cerebrovascular protection.86 Mokou et al. proposed an integrated, multilayered approach that leverages crossomics analyses of publicly available transcriptomic and proteomic data and uses the Connectivity Map tool to identify potential repurposed drugs for bladder cancer treatment.87 The antidepressant propylidine was found to mediate its effects by inducing cell cycle arrest and inhibiting DNA repair processes (both homologous recombination and nonhomologous end joining), effectively blocking the growth of both triple-negative and estrogen receptor-positive breast cancer cells.88 Multiomics technology facilitates high-throughput screening of numerous known drugs, enabling the rapid identification of compounds with potential new indications. For example, the Butte laboratory employed bioinformatics tools to analyze gene expression data from diverse diseases and cell treatments in public databases. By comparing disease-specific and drug-specific gene expression profiles, they identified cimetidine—a commonly used ulcer drug—as an inhibitor of lung adenocarcinoma.89 Lee et al. developed a clinically aligned, single-cell-resolved screening platform to evaluate repurposed neuroactive drugs systematically via the use of surgical specimens from patients with glioblastoma. Profiling over 2500 ex vivo drug responses across 132 compounds from 27 patients identified several neuroactive drug classes with strong anti-glioblastoma efficacy. Notably, the antidepressant vortioxetine was shown to induce glioblastoma regression through Ca2 + -dependent activation of the AP-1/BTG signaling axis.90,91 In addition, the antiepileptic drug topiramate was found to significantly alleviate inflammatory bowel disease (IBD).92 By analyzing the multiomics profiles of both drugs and diseases, precise matching between the two can be achieved, enabling more accurate target and indication selections for novel drug applications. In cancer research, for example, multiomics analysis can reveal the genetic, transcriptional, and metabolic features of cancer, as well as interactions between cancer cells and their microenvironment, thereby refining drug target identification and therapeutic strategies. Furthermore, drug repositioning has emerged as a promising strategy for treating rare diseases. Nonfunctional pituitary neuroendocrine tumors, which are notoriously difficult to diagnose clinically, were addressed by Aydin et al., who developed a feature-based drug repositioning method through the integration of multiomics data, including epigenomic and transcriptomic profiles. This approach identified palbociclib and linifanib as potential therapeutic agents for these tumors.93
Full size table
The current frontier in drug repurposing emphasizes the development of multiomics-driven repositioning platforms. Multiomics analyses were employed to assess ovarian cancer cell sensitivity to glucose starvation at the clonal level, revealing that glucose deprivation-resistant (GDR) clones presented greater sensitivity to metformin, a mitochondrial respiratory chain complex I inhibitor, than glucose deprivation-sensitive (GDS) clones did. These findings suggest potential therapeutic strategies targeting oxphos-dependent metabolic pathways in this subgroup.94 Deterministic barcode histospatial sequencing (DBiT-seq), introduced by Liu et al., represents a groundbreaking spatial multiomics technology that simultaneously localizes mRNA and protein in formaldehyde-fixed tissue slides via next-generation sequencing.95 When applied to mouse embryos across various tissue types and stages of early organogenesis, the gene expression profile at 10 μm pixel resolution aligns with single-cell transcriptomic clusters, enabling rapid identification of cell types and spatial distribution mapping. This technique also uncovers heterogeneous drug responses within the tissue microenvironment.96 In addition, microbiome‒host multiomics interaction analysis has provided new insights, particularly in relation to the role of the gut microbiota in shaping immunotherapy outcomes. The antidiabetic drug acarbose was shown to increase CXCL10 expression through the tryptophan metabolite indole acetate, promoting CD8 + T-cell recruitment and significantly enhancing the antitumor response to PD-1 therapy in female tumor-bearing mice.97
Despite these advancements, several challenges remain. The insufficient temporal resolution of multiomics data may obscure dose-dependent effects, and discrepancies in multiomics responses between preclinical models (e.g., organoids) and real patient data highlight the need for bridging prospective cohorts (e.g., the UK Biobank). In the future, the integration of causal inference algorithms (such as MR) with cross-species multiomics validation is expected to establish a closed-loop repositioning system—“from computational prediction to clinical evidence”—fundamentally transforming the economics and speed of drug development.
Application of multiomics to original compound discovery
The deep integration of multiomics technologies is revolutionizing the discovery process for novel drug compounds,98,99,100 offering innovative strategies for natural product discovery and synthetic chemical design by systematically analyzing the biosynthesis mechanisms, action networks, and evolutionary logic of bioactive molecules (Table 3). Multiomics techniques enable the identification of key genes involved in the biosynthesis of active ingredients. For example, in a study of Salvia miltiorrhiza, transcriptomics and metabolomics identified multiple genes associated with the biosynthesis of tanshinones and phenolic acids, including members of the cytochrome P450 gene family that play a role in tanshinone production, laying the foundation for further exploration of these biosynthetic pathways.92,101 Celastrol, a bioactive triterpenoid natural product derived from Tripterygium wilfordii roots, exhibits potent antimicrobial activity through dual mechanisms. Yuan et al. demonstrated, via integrated transcriptomic, proteomic, and metabolomic profiling, that celastrol binds directly to Δ¹-pyrroline-5-carboxylate dehydrogenase (P5CDH), inducing lethal oxidative stress while also inhibiting de novo DNA synthesis in target pathogens.102 Soares et al. utilized multiomics technologies to gain deeper insights into two recently discovered nature-inspired anticancer compounds (SIMR3066 and SIMR3058), revealing their anticancer effects at both the proteomic and metabolomic levels.103 Traditional compound discovery relies on phenotypic screening or single-target approaches; however, the multiomics-driven “systematic mining” model reveals dynamic associations between biosynthesis-related gene clusters and secondary metabolites through genome‒metabolome‒proteome collaborative analysis, greatly improving the efficiency of active molecule discovery. Many traditional Chinese medicine (TCM) compounds, although widely used clinically, lack clarity regarding their bioactive ingredients and mechanisms of action, limiting their broad application. Multiomics analysis plays a pivotal role in elucidating the metabolic regulatory mechanisms involved in the biosynthesis of these active compounds. For example, analyzing transcriptomic and metabolomic changes in Salvia miltiorrhiza hairy roots under various induction conditions revealed that signaling molecules such as methyl jasmonate significantly regulate tanshinone biosynthesis.104,105,106 Key transcription factors and metabolic pathways involved in this regulatory network were identified, providing a theoretical basis for optimizing tanshinone yield through metabolic engineering.101 Ding et al. applied an integrated cardiac mitochondrial metabolomics and proteomics platform to systematically identify mitochondrial-targeting bioactive constituents in Sini decoction. This approach identified multiple compounds that simultaneously address cardiac bioenergetic deficits and mitochondrial dysfunction, thereby mitigating doxorubicin-induced cardiomyopathy. This work establishes a high-throughput screening paradigm for discovering mitochondrial-protective compounds within complex natural product matrices.107 Further research by Ma et al. integrated serum pharmacochemistry, multiomics, network pharmacology, and validation experiments to examine the effects of Qichaoshengbai capsules on a mouse leukopenia model, identifying the leukotriene pathway as a key player and ALOX5 as a potential target.108 Similarly, Ye et al. combined transcriptomic, metabolomic, and network pharmacological analyses to demonstrate that Dengzhan Shengmai capsule and its active components, baicalein and quercetin, regulate the NF-κB signaling pathway, whereas compounds such as schisandrin, apigenin, and schisandrin B exhibit antithrombotic activity.86 The gut microbiota is also a focal point in anti-drug resistance research. Cheng et al. integrated whole-genome sequencing (WGS) of symbiotic gut microbial isolates with metabolomic analysis, revealing that the gut microbiome produces metabolites, including dipeptides, with potential applications in anti-infective drugs, particularly those against antibiotic-resistant pathogens. This research has paved the way for new pathways to antibacterial lead structures.109
Full size table
Current cutting-edge research is increasingly focused on identifying multidimensional molecular compounds. Single-cell multiomics techniques (e.g., scRNA-seq combined with scMetabolomics) shed light on the roles of rare metabolites in host‒microbial interactions, such as indole derivatives produced by intestinal symbiosis, which regulate immune homeostasis through the activation of host aromatic hydrocarbon receptors (AhRs).110 These molecules can be chemically modified into lead compounds for treating inflammation, oxidative stress injuries, cancer, aging-related diseases, and other conditions.111,112 Liu et al. identified that the colorectal cancer-associated gut microbiota was linked to elevated D-amino acid metabolism and butyrate metabolism through analysis of a metagenomic dataset comprising 1,368 samples from eight geographically distinct cohorts.113,114 Single-cell multiomics has made significant strides in elucidating spatiotemporal dynamics and polymorphisms within the immune system.115 Collora et al. employed single-cell ECCITE-seq (Expanded CRISPR-compatible Cellular Indexing of Transcriptomes and Epitopes by Sequencing) to simultaneously capture surface protein expression, transcriptomes, and HIV-1 RNA and T-cell receptor (TCR) sequences within individual cells.116 Their study revealed that HIV-1 RNA + T-cell clones exhibit larger clonal sizes, become established during viremia, persist after viral suppression, and are enriched in GZMB+ cytotoxic effector memory Th1 cells. Targeting these infected cytotoxic CD4 + T cells and drivers of clonal expansion offers a novel strategic direction for HIV-1 eradication.117 Similarly, Unterman et al. reported dysregulated MHC-II/LAG-3 interactions on myeloid and T cells in patients with COVID-19, revealing desynchronization between innate and adaptive immunity in progressive COVID-19.118
In synthetic chemistry, multiomics techniques facilitate the integration of directed evolution with rational design. Genomic screening, combined with CRISPRi and metabolic flux analysis, enables the identification of critical regulatory nodes within microbial synthesis pathways. Anglada-Girotto et al. developed a comprehensive, unbiased framework to create a reference map of CRISPRi-induced metabolic changes across 352 genes involved in key biological processes, allowing for high-throughput functional annotation of an E. coli compound library. This approach serves as a universal strategy for high-throughput analysis of compound functions, extending from bacterial models to human cell lines.119 Understanding the cellular response to drugs is essential for elucidating the mechanisms of action of small molecules. Mitchell et al. developed a high-throughput proteomic screen using 96-well plates to analyze 875 compounds in human cancer cell lines. By constructing protein‒protein and compound‒compound correlation networks, they revealed the mechanisms of action of several compounds and identified off-target pharmacology within the compound library. Proteins, as essential drug targets, are linked to disease mechanisms through large-scale GWAS, with multilevel integration revealing genetic variations impacting protein functions.120 Yang et al. utilized multitissue (cerebrospinal fluid, plasma, and brain) protein quantitative trait loci as instrumental variables in MR and colocalization analysis. Depending on the tissue, between one and three proteins are linked to drug compounds for at least one phenotype in DrugBank and ChEMBL, potentially paving the way for new interventions for complex diseases such as ovarian and lung cancer.121 In prostate cancer research, the major coumarins verdilonolactone and demethylvedilonolactone were studied via an integrated approach that combined spatial metabolomics with liver-specific transcriptomics. This multiomics platform enabled the mapping of the biological distribution and metabolism of these compounds in zebrafish, revealing that the hepatoprotective effects of verdilonolactone primarily involve steroid biosynthesis and fatty acid metabolism.122
However, challenges persist in the field. The lack of standardized multiomics data across species limits the development of universal models, whereas the complexity of biosynthesis in natural product chemical structures necessitates the integration of quantum computing and synthetic biology. In addition, bridging the differences in titer between in vivo and in vitro active compounds requires the creation of organoid-based multiomics models, such as liver organoid pharmacoproteogenomics.123 The combination of automated multiomics platforms (e.g., Lab-of-the-Future) and causal reasoning algorithms (e.g., structural equation models)124,125 holds promise for accelerating the entire drug discovery process—from “gene cluster prediction to preclinical candidate molecules”—ushering in a shift from traditional “trial and error” screening to a new era of “programmable creation.”
The role of artificial intelligence in drug discovery
Multiomics-based drug discovery encounters several challenges, including data complexity, inefficient target discovery, design bottlenecks, and difficulties in clinical trial design. AI offers a promising solution to these issues.24,47 With its capabilities in big data processing, dimensionality reduction, and feature selection, AI improves the efficiency of multiomics data analysis, playing a pivotal role in target discovery, drug design, and the optimization of clinical trial design. The applications of AI span the entire drug development lifecycle, as illustrated in Fig. 1. I systems enable high-throughput processing of multidimensional datasets (e.g., genomic landscapes and biomarker profiles), accelerating novel target identification. Simultaneously, virtual screening platforms use DL architectures to computationally prioritize compounds that interact with targets, significantly enhancing hit identification efficiency.126 Through DL and ML algorithms, cognitive intelligence predicts drug molecule structures and properties and supports de novo drug design, structural optimization, and absorption, distribution, metabolism, excretion, and toxicity (ADMET) property forecasting, which reduces the likelihood of research failure.127 Patient stratification by molecular profiling (integrating genomic and clinical datasets) enables precision cohort enrollment. Concurrently, digital twin platforms leverage real-world evidence to simulate therapeutic outcomes in silico, thereby optimizing trial design and refining dosing regimens. Transformative intelligence focuses on innovating and optimizing the R&D process, such as enhancing clinical trial design by analyzing multimodal data, improving patient recruitment efficiency and accuracy, shortening trial cycles, and contributing to drug repositioning to add new value to existing drugs.128 Virtual screening of chemical libraries is systematically employed to identify candidate compounds, whereas de novo molecular design is driven by advanced AI architectures, including RL and GANs. Structure-based and ligand-based drug design methodologies are synergistically utilized for binding affinity prediction and molecular refinement. Retrosynthetic pathway planning is conducted through DL frameworks, such as transformer architectures, enabling efficient synthetic route design. AI-driven robotic synthesis platforms, integrated with automated instrumentation, facilitate high-throughput compound synthesis for rapid lead optimization. AI has already been successfully incorporated into multiomics data analysis and electronic health records (EHRs), advancing precision medicine by identifying novel biomarkers and therapeutic targets.129 Moreover, AI has demonstrated substantial potential in improving diagnostic accuracy and treatment selection for cancers, such as non-small cell lung cancer and esophageal cancer, by analyzing multiomics data to predict treatment response.130 A key breakthrough of AI lies in its capacity to extract hidden patterns from vast, heterogeneous datasets, such as protein structure databases, such as ChEMBL, and patient multiomics databases, such as the UK Biobank, enabling the full molecular pipeline—from generation and target prediction to efficacy optimization and toxicity assessment. However, challenges remain in integrating AI into clinical settings, including data harmonization, algorithm interpretability, and ethical considerations. Addressing these issues is essential to ensure the successful implementation of AI-driven solutions in healthcare.131 As the field progresses, the collaboration between AI and multiomics is poised to transform our understanding of complex diseases and enhance patient care through more personalized approaches.132
The alternative text for this image may have been generated using AI.
Full size image
Applications of multiomics in drug discovery. The integration of multiomics data could aid in target discovery, biomarker identification, drug repurposing, compound discovery, and clinical trial design, and further contribute to patient stratification and precision medicine
The application of artificial intelligence for drug design
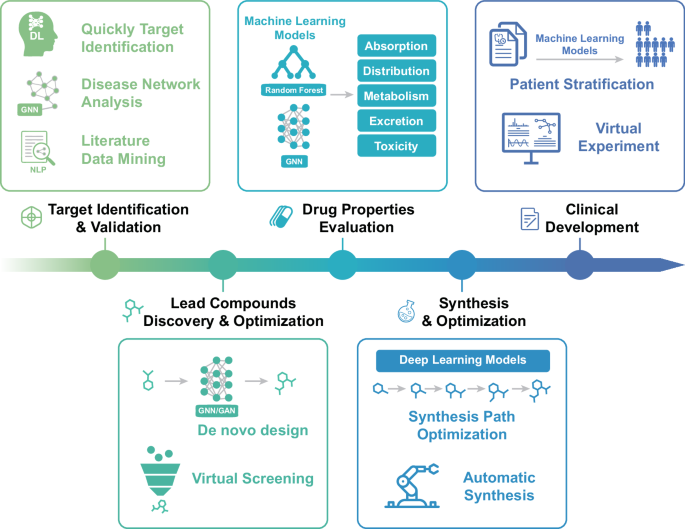
By integrating DL, generative models, and multiscale biological data, AI overcomes the inefficiencies associated with traditional trial-and-error approaches.133 This transformative shift is enabling a paradigm shift toward “rational design” and “automated creation” in drug research (Fig. 2). ML models, such as RF and gradient-boosting classifiers, outperform conventional methods in predicting molecular activity and toxicity, streamlining the drug discovery process and reducing costs.134,135 A virtual screening strategy that combines ML with molecular docking efficiently screens billions of compounds at a fraction of the cost of traditional methods. Directed message passing neural networks (D-MPNNs) were employed for the discovery of novel antibiotics that target Escherichia coli and Acinetobacter baumannii.59,136 Antimicrobial activity prediction models were trained exclusively on binary growth inhibition data specific to each target pathogen. These validated models prioritized compounds within the Drug Repurposing Hub, a curated library of ~7000 agents with favorable toxicity and PK profiles.137,138 In addition, advanced ML frameworks have demonstrated the ability to generate novel molecular structures, thus facilitating the discovery of innovative therapeutic agents.139,140,141 Recent studies highlight the transformative potential of AI in overcoming previously insurmountable challenges in drug discovery. For example, in idiopathic pulmonary fibrosis (IPF), where long-researched drug targets fail to produce clinically effective treatments, Ren et al. employed predictive AI methods to identify TRAF2- and NCK-interacting kinase (TNIK) as promising antifibrotic targets. This approach led to the rapid development of INS018_055, a small-molecule TNIK inhibitor with favorable drug-like properties and broad antifibrotic activity, which was achieved in just 18 months, demonstrating the power of AI-driven drug discovery.142 Furthermore, AI is advancing novel therapeutic strategies, such as targeted protein degradation, which induces proteins to interact with E3 ubiquitin ligases, triggering degradation. Despite challenges in identifying a broad array of targets, Mayor-Ruiz et al. introduced a chemical screening method based on deconvolutional motion and thermogenic targeting in low-source cells, identifying compounds that induce the ubiquitination and degradation of CYCLIN K. By enhancing the interaction between CDK12-CYCLIN K and the CRL4B ligase complex, this method significantly improved drug target discovery efficiency.98 Recent developments in generative models, such as generative tensor reinforcement learning (GENTRL), highlight AI’s potential in small-molecule design. GENTRL facilitates the creation of novel compounds optimized for synthetic feasibility, novelty, and biological activity. For example, GENTRL was used to identify a potent inhibitor of discoidin domain receptor 1 (DDR1), a kinase involved in fibrosis and other diseases, within 21 days. Several compounds have shown activity in biochemical assays, with two demonstrating promise in cell assays and one leading candidate exhibiting favorable pharmacokinetics in mice. These examples illustrate AI’s capacity to accelerate and enhance drug design, unlocking new opportunities for developing transformative therapeutics.143
The alternative text for this image may have been generated using AI.
Full size image
Artificial intelligence for drug design. Artificial intelligence could assist drug design in various stages, including target identification, lead compound discovery, drug property evaluation, compound synthesis and optimization, and clinical development. DL Deep learning, GNN graph neural network, NLP natural language processing, GAN generative adversarial network
The frontier of drug discovery is advancing through collaborative innovation driven by multimodal AI. GNNs are increasingly utilized to predict drug targets and their corresponding small-molecule ligands by integrating diverse datasets, including genomic variations, protein interaction networks, and cell phenotypic data.144 Neural network models enable the identification of pharmacophore-informed substructures predictive of antibiotic activity, facilitating the anticipation of structural classes.145,146,147 Wong et al. developed an explainable, substructure-based methodology for efficient DL-guided exploration of chemical space. By characterizing the antibiotic activity and human cell cytotoxicity profiles of 39,312 compounds, they deployed an ensemble of GNNs to predict these properties for 12,076,365 compounds. Empirical validation of 283 compounds revealed that hit compounds exhibiting antibiotic activity against Staphylococcus aureus showed structural class enrichment of putative scaffolds derived from first principles.148 Zhan et al. engineered a GNN-based feature extractor, a curriculum learning-optimized strategy, and a Learning Binary Neural Tree (LBNT) predictor to achieve enhanced accuracy in determining molecular property endpoints.149,150 Olivecrona et al. demonstrated the potential of recurrent neural networks (RNNs) enhanced with strategy-based RL to generate analogs of celecoxib and sulfur-free compounds.151 The use of graph convolutional networks, which simulate chemical molecules without relying on two-dimensional representations, has significantly improved molecular generation capabilities. In addition, GANs, which leverage both generator and discriminator networks to refine generator models, have become widely adopted in molecular generation tasks.152 AI-driven drug screening technologies are transforming the drug discovery process, enabling rapid identification and evaluation of novel compounds. For example, Tu et al. combined AI approaches, including large language models and GNNs, to identify and screen the compound HG9-91-01, which targets RIPK3 and has neuroprotective effects in acute glaucoma.153 In formulation strategy design, AI addresses long-standing challenges in drug development. FormulationDT, the first data-driven and knowledge-led AI platform, employs a systematic approach to rational formulation design by drawing insights from approved drug formulations and incorporating 12 key decisions spanning oral and injectable dosing strategies. Wang further enhanced this platform by creating the first dataset of approved drug formulations and developing the PU-decide framework, which enables the construction of accurate, interpretable classification models for each decision point. This platform has proven valuable in designing PROTACs, improving their efficiency, and mitigating risks throughout the drug development lifecycle.154
However, AI-driven drug discovery faces substantial limitations. This process generates voluminous datasets with highly heterogeneous data quality.155,156 Data from diverse laboratories, equipment, and experimental conditions often contain measurement artifacts, missing values, and batch effects—issues that are particularly critical given the reliance of ML models on data integrity. Furthermore, complex models, such as DNNs, often function as “black-box” systems with opaque decision-making processes, hindering the mechanistic interpretation of predictions. In pharmaceutical contexts, understanding the rationale behind models is essential for analyzing the mechanism of action (MoA) and safety profiles of drugs; this lack of interpretability presents significant translational challenges.157 Although research has demonstrated that integrating biomedical networks with baseline drug‒drug interaction (DDI) maps can mitigate supervised data scarcity by leveraging rich pharmacological knowledge,158 issues related to data dependency and reliability remain. In the realm of de novo molecular generation, current generative models present several shortcomings, including limited chemical novelty, structural redundancy compared with training sets, synthetic infeasibility of proposed compounds, and insufficient bioactivity validation of generated molecules.159,160,161 The scarcity of high-quality training data limits model generalizability, and the absence of interpretability in black-box models increases the risk of unforeseen off-target effects. By establishing an intelligent ecosystem that integrates “generation–verification–iteration,” AI is poised to reduce the cost and cycle time of new drug R&D to one-tenth of the traditional model, marking the true advent of the precision era in “on-demand medicine.”
Application of artificial intelligence in predicting drug interactions
The prediction of DDIs is crucial for ensuring patient safety, particularly given the increasing prevalence of polypharmacy. DDIs are fundamentally driven by PK and PD determinants (Fig. 3). AI has multiple capabilities in this area: it predicts absorption kinetics, metabolic stability profiles, and elimination pathways; facilitates the identification of metabolic routes and reactive intermediates for toxicological risk assessment through integration with high-resolution mass spectrometry; enables dose individualization and DDI early-warning systems by synthesizing patient-specific parameters, such as genotypic variations and hepatic/renal function metrics; and forecasts personalized dosing regimens while simulating PK changes in polypharmacy scenarios. Simultaneously, supervised learning models are employed to quantify drug-target binding affinities and predict synergistic or antagonistic pharmacological effects. For biomarker discovery and therapeutic efficacy prediction, AI performs cluster analysis of EHRs to stratify patient subpopulations on the basis of differential drug responsiveness while also anticipating susceptibility to adverse events. Dynamic PD modeling further integrates AI with physiologically based PK simulations to reconstruct concentration‒effect relationships and project combinatorial drug effects. AI models have been developed to analyze complex drug interactions, identifying potential adverse effects before they manifest in clinical settings (Table 4). AI is revolutionizing DDI prediction by overcoming the limitations of traditional quantitative structure‒activity relationship (QSAR) models, which are often constrained by their linear nature.162 AI techniques, particularly ML, deconstruct the intricate relationships among pharmacodynamics, pharmacokinetics, and molecular networks, providing a more comprehensive understanding of drug interactions.163 Algorithms such as logistic regression, RF, and support vector machines (SVMs) have been widely applied to predict DDIs, efficiently process large datasets, and identify critical features contributing to drug interactions.164 Wang et al. developed a series of high-performance predictive models for drug-metabolizing DDIs on the basis of substrates and inhibitors of five cytochrome P450 isoenzymes. Using ML methods such as RF and XGBoost, along with four descriptor types (MOE_2D, CATS, ECFP4, and MACCS), they predicted potential DDIs among FDA-approved drugs, identifying 54,013 possible drug pairs that may exhibit DDIs.165 DL frameworks leveraging molecular graph representations have further enhanced DDI prediction by focusing on substructure interactions instead of entire molecular structures.166 This approach improves predictive accuracy, offering more reliable predictions than traditional methods do.167,168 Moreover, AI-driven systems can analyze vast datasets of historical DDI information, revealing novel interactions that may not be immediately apparent via conventional techniques.169 This capability is especially valuable in drug repurposing, where existing drugs are assessed for new therapeutic applications on the basis of their interaction profiles.170 J et al. proposed a DL-based DDI prediction model, DrugSchizoNet, to address challenges such as data imbalance, noise, poor generalization, high costs, and time-consuming processes. Using drug-related data from the DrugBank and repoDB databases, DrugSchizoNet successfully predicted drug–target interactions (DTIs) in patients with schizophrenia, demonstrating the potential of DL to advance drug discovery and development.171
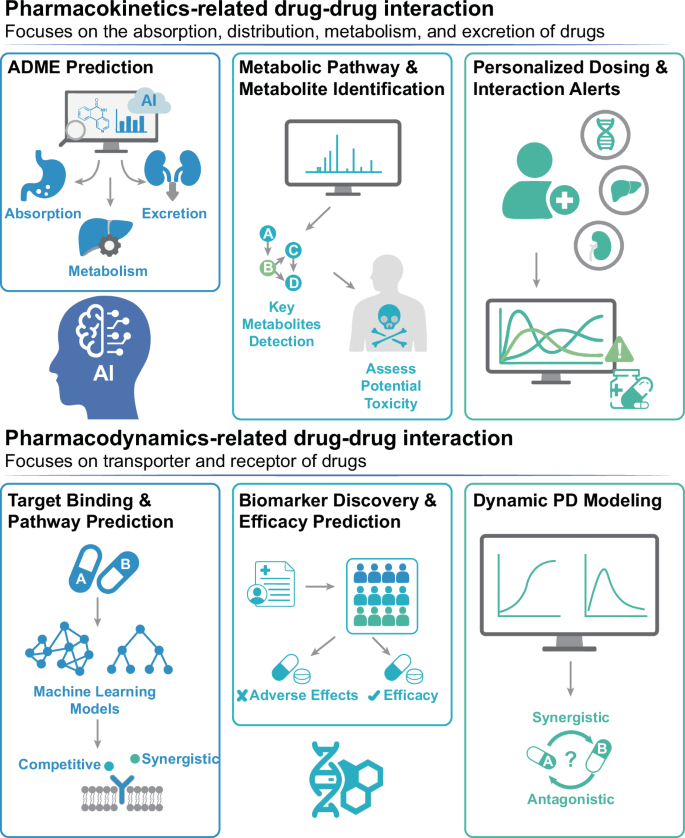
The alternative text for this image may have been generated using AI.
Full size image
Artificial intelligence for predicting drug‒drug interactions. Artificial intelligence could assist in drug‒drug interaction prediction from the perspective of both pharmacokinetics and pharmacodynamics. AI artificial intelligence, ADME absorption, distribution, metabolism, and excretion
Full size table
Convolutional neural networks (CNNs) are highly effective at identifying spatial patterns in molecular structures, making them particularly suitable for predicting drug interactions on the basis of molecular features.172 In addition, GNNs are designed to handle graph-structured data, making them ideal for modeling drug interactions within a network context. By representing drugs and proteins as nodes in a graph, GNNs learn interactions by aggregating features from neighboring nodes. This approach has been successfully applied to predict DTIs and DDIs, with techniques such as residual graph convolutional networks (RGCNs) and graph autoencoders (GAEs) achieving notable improvements in prediction accuracy.173,174 An RNN is another architecture capable of processing sequential elements through recurrent hidden layer operations. In RNNs, the hidden state from the preceding timestep serves as input for the current timestep, capturing dynamic temporal patterns within sequences.175,176 Variants of RNNs, including long short-term memory (LSTM) and gated recurrent units (GRUs), have demonstrated superior performance in mitigating vanishing gradient issues and modeling long-range dependencies.177 In contrast, GNNs have distinct advantages when novel drugs or drug combinations are used, as they leverage topological information and node attributes within graph structures. This architecture facilitates inductive inference for unobserved drugs or interaction patterns in training sets through structural feature extrapolation.178 On the other hand, RNNs may require extensive data to generalize to novel sequence patterns or molecular scaffolds, making them particularly suitable for processing sequence-characterized DDI data, such as medication administration timelines and SMILES-encoded molecular representations. For example, when analyzing patient medication histories to predict DDIs, RNNs effectively model temporal dependencies and sequential relationships in drug exposure.179 Thus, model selection between GNNs and RNNs should be guided by the inherent data characteristics and the specific prediction objectives. Zhang et al. introduced a hybrid model that combines RNNs and CNNs for biomedical relationship extraction. This model generates the shortest dependency path on the basis of the dependency graph of candidate sentences and extracts biomedical relationships by combining the output features from both RNNs and CNNs. When evaluated via five common protein‒protein interaction (PPI) corpora and one DDI corpus, the model showed significant improvement in performance over traditional methods.180 Transformer models, known for their capacity to capture long-range dependencies in sequences, have also been adapted for drug interaction prediction.181 Zaikis et al. proposed an end-to-end, joint multitask DDI extraction model based on transformers, which integrates domain knowledge and shared parameter layers within a dynamic drug entity extraction and interaction classification architecture. By incorporating a dynamic attention mechanism with task-specific focus and a dynamic loss function, this model enhances the extraction process. It can generate variable outputs on the basis of identified drug entities within a single framework, providing high accuracy in predicting interactions by capturing complex dependencies in biological sequences.182 These models are well-suited for handling large-scale biological data, offering significant improvements in interaction prediction accuracy.
Despite recent advances, the field faces three critical paradoxes: (1) The data heterogeneity dilemma—Disparities in spatiotemporal resolution between single-cell transcriptomics and population PK data introduce biases when extrapolating pharmacological effects across tissues, resulting in significant prediction errors, particularly in the association between hepatic CYP enzyme systems183 and blood‒brain barrier (BBB) permeability.184,185 (2) The interpretability gap—explaining attention-based mechanisms in alignment with traditional pharmacological concepts, such as receptor occupancy or the enzyme inhibition constant (Ki), proves challenging,186 undermining clinical trust in decision-making processes. (3) The dynamic system modeling deficiency—Current models predominantly focus on static binding affinities, overlooking the influence of time-varying drug concentration curves on DDI networks, which creates prediction gaps, such as those seen in time-dependent CYP3A4 inhibition.187,188 Furthermore, the clinical translation of DDI predictions faces a “broken validation loop.” The throughput of automated experimental platforms, such as organ-on-a-chip and high-throughput screening of organoids, struggles to keep pace with the speed of AI-generated hypotheses. In addition, the fragmentation of real-world data (RWD) amplifies the risks associated with model generalization. Future breakthroughs will likely hinge on the seamless integration of cross-scale simulation infrastructures, spanning from molecular dynamics to digital twin patients, alongside federated learning paradigms, to establish a closed-loop ecosystem for DDI prediction, validation, and optimization.
Application of artificial intelligence in predicting drug safety
In the advanced stages of drug development, evaluating the toxicity profiles of new compounds is critical. Drug safety assessment plays a pivotal role, yet it is a complex process requiring extensive datasets, including in vivo data from clinical studies. AI facilitates comprehensive safety profiling across three key phases: GLP-compliant preclinical safety assessment, clinical trial protocol optimization and risk surveillance, and postmarketing pharmacovigilance intelligence. Traditional methods rely heavily on animal testing, in vitro toxicity assays, and clinical observations, each of which faces limitations, including prolonged timelines, high costs, and uncertainties in species extrapolation. AI enhances early-stage discovery and preclinical screening through computational toxicity prediction. AI models—incorporating ML and DL architectures—analyze chemical structures via QSAR modeling, high-throughput screening bioassay data, and multiomics profiles to predict various toxicity endpoints, such as cardiotoxicity, hepatotoxicity, mutagenicity, and carcinogenicity.
ADMET profiling aids in eliminating compounds with suboptimal safety margins or PK liabilities. Simultaneously, off-target interaction predictions help identify unintended biological interactions that may lead to adverse effects. AI further reduces reliance on animal testing by enabling intelligent experimental prioritization, directing resources toward high-value in vitro and in vivo validation.189,190 Recent advancements in AI have revolutionized toxicity assessment by integrating diverse datasets to construct high-precision predictive models (Table 5). These innovations provide robust tools for the early detection of adverse drug reactions (ADRs), optimization of molecular structures, and mitigation of clinical trial failures. However, challenges remain, including model interpretability, data quality, and the reliability of cross-species predictions (Fig. 4). Cardiotoxicity and hepatotoxicity are critical toxicities evaluated during drug development. Early prediction of these toxicities can significantly reduce the risk of compound failure. Several research groups have leveraged AI methods to address this challenge.191,192,193 For example, Mamoshina et al. explored the feasibility of using AI-based models to predict cardiotoxicity across various compounds. They developed a model capable of predicting cardiotoxicity by analyzing drug properties from publicly available datasets, such as DrugBank and medDRA. The model showed strong predictive performance, achieving an area under the curve (AUC) of 79% for the validation data and 66% for the unseen data, effectively distinguishing between safe and at-risk drugs.194 AI-based methodologies have also been applied to predict drug-induced liver injury, achieving a classification accuracy of 89%.195 In addition, using graph embedding techniques, Joshi designed and trained a customized DNN called KGDNN (knowledge graph DNN) for ADR prediction. This model achieved an AUROC of 0.917, which was validated through two case studies on drugs causing liver injury and COVID-19-recommended drugs.196 Drug-induced kidney injury (DIKI) poses significant challenges during drug development, often resulting in failure at the clinical stage. Early prediction of DIKI risk can increase drug safety and development efficiency. Existing models often focus solely on physicochemical properties and frequently overlook drug‒target interactions, which are crucial for DIKI. Rao et al. compiled a dataset comprising 231 non-nephrotoxic and 129 nephrotoxic compounds. AI/ML integration models incorporating both physicochemical properties and off-target interaction data significantly improved the accuracy of DIKI predictions.197 Liu et al. emphasized that off-target drug interactions and associated ADRs are vital factors impacting drug safety. To assess the resistance of candidate drugs, they developed an AI model to accurately predict compound off-target interactions via a multitask GNN.198 These advancements highlight AI’s potential in enhancing drug safety assessments and expediting the drug development process. AI operates across three critical domains of pharmaceutical safety evaluation: During clinical trial optimization and surveillance, AI analyzes patient-level data to perform risk-stratified cohorting, identifying individuals with a higher risk of specific ADRs while refining protocol eligibility criteria.199 AI also enables early signal detection by computationally mining clinical trial narratives to uncover emerging safety concerns. In parallel, AI models integrate multifactorial data to quantify the probability of trial failure on the basis of safety endpoint projections. For postmarketing pharmacovigilance, AI enhances signal detection by processing high-dimensional safety data sourced from structured repositories (e.g., FAERS, VigiBase) and real-world evidence (e.g., EHRs, insurance claims, social media). Through natural language processing and ML algorithms, AI accelerates the identification of drug‒adverse event associations, including rare adverse outcomes. Within ADR characterization and causality assessment frameworks, AI computes probabilistic causal inference scores via temporality analysis and medical history confounder adjustments while extracting detailed ADR phenotypes from unstructured reports via deep natural language processing architectures. Ultimately, AI-driven risk subpopulation prediction based on RWD provides evidence-based prescribing optimization and personalized risk mitigation strategies.
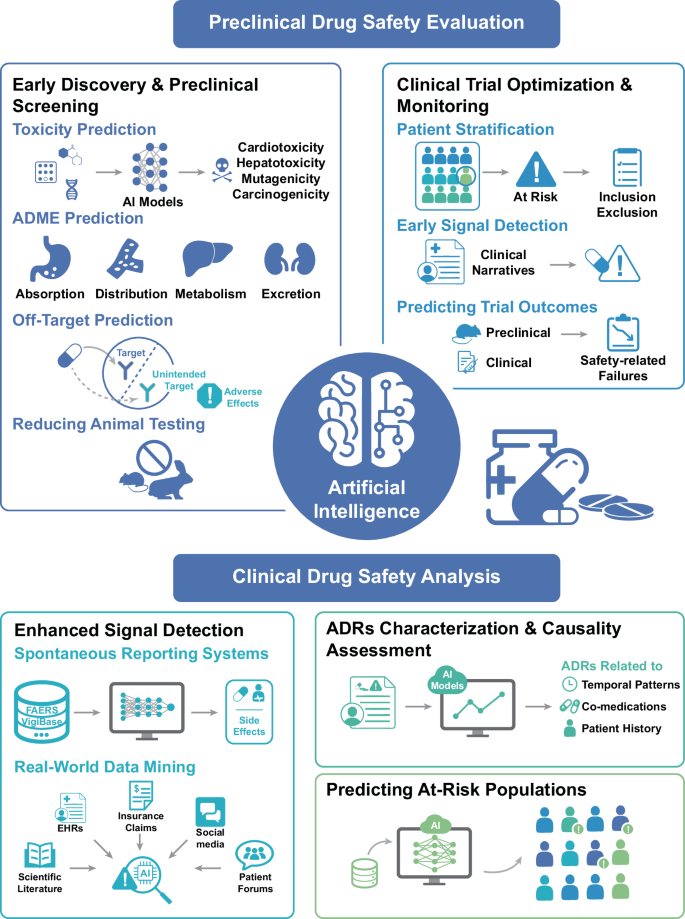
The alternative text for this image may have been generated using AI.
Full size image
Artificial intelligence for drug safety prediction. Artificial intelligence could assist drug safety prediction in preclinical, clinical, and postmarket stages. AI artificial intelligence, FAERS FDA adverse event reporting system, EHRs electronic health records, ADRs adverse drug reactions
Full size table
The next generation of AI toxicity prediction systems is expected to follow three key trends: first, integrating self-monitoring and federated learning to create a cross-species, cross-modal knowledge framework; second, developing dynamic toxicity early warning models based on real-time, multigroup data from organ chips to optimize the “dry‒wet closed loop”; and third, combining RL and automated synthesis platforms to build a molecular pipeline for trade-weighted molecules. Ultimately, the collaboration between data-driven approaches and mechanistic reasoning will shift drug safety evaluation from an empirical guide to a predictive, priority-based paradigm. However, overcoming data barriers, enhancing model transparency, and developing human‒computer collaborative validation systems are essential to fully realizing the transformative potential of AI in ensuring global drug safety.
Representative examples of drug development via multiomics and artificial intelligence integration
The drug development process is a complex journey comprising several critical stages, each contributing to the creation of a new prescription medication. These stages include drug target identification and validation, lead compound optimization, preclinical pharmacology and toxicology studies, and clinical trials. On average, bringing a new drug to market requires substantial pretax investment, with only ~10% of projects succeeding during the discovery and development phases.200
AI has significantly accelerated target discovery in drug development. Multiomics integration models, particularly those based on GNNs, can predict potential targets and off-target effects.201 Knowledge profiles such as MetaG and MetaT aid in uncovering nonclassical targets, such as RNA-binding proteins, involved in bacterial community dynamics.202 AI models, especially those utilizing transformer-based architectures,203,204 improve compound structure predictions by incorporating genome-encoded enzyme catalysis rules, molecular skeleton diversity from metabolomics, and target-binding patterns derived from proteomics. With the use of SMILES and DeepSMILES representations, these models are trained on diverse datasets, including COVID-19-related data, biometric data, and other molecular and biological properties, enhancing their molecular prediction capabilities.205 Simultaneously, scGPT emerged as the first single-cell foundation model employing a generative pretrained transformer architecture trained on a curated corpus of 33 million normal human cell transcriptomes from CELLxGENE Discover, covering 51 distinct organs/tissues across 441 independent studies. This paradigm has since been expanded by large-scale successors such as cFoundation and scBOL. These models exhibit versatile capabilities in executing multimodal computational biology workflows, such as precise cross-tissue cell type annotation, robust multibatch integration to mitigate technical artifacts, multiomics data alignment (e.g., scRNA-seq/scATAC-seq coembedding), in silico perturbation response prediction (CRISPRi/chemical perturbations), and context-aware gene regulatory network inference.10,206,207,208 The complexity of the gut microbial ecosystem requires the integration of metagenomics, metatranscriptomics, metabolomics, and metaproteomics to achieve a comprehensive characterization of the gut microbiota. This generates vast amounts of data that must be synthesized to yield clinically meaningful insights. AI and ML have increasingly been applied to multiomics datasets in various contexts related to microbiome dysbiosis, ranging from chronic diseases to cancer. These tools hold substantial promise for clinical applications, including the discovery of microbial biomarkers for disease classification and prediction, the prediction of responses to specific treatments, and the refinement of microbiome-modulating therapies.209,210 In IBD, AI and ML algorithms have proven useful in identifying microbial signatures and dysbiosis patterns linked to disease onset, progression, and treatment response.211 In one large multicohort study involving nearly 6000 metagenomes, an RF model achieved high accuracy (AUC > 0.90) in identifying specific bacterial clusters that could differentiate IBD patients from healthy controls, as well as from patients with Crohn’s disease or ulcerative colitis.212 Comparable results were obtained by employing AI-driven tools to analyze microbial data from metagenomics, metatranscriptomics, metabolomics, proteomics, and host fecal calprotectin levels.213 In oncology, the integration of AI with multiomics data has been effective in identifying biomarkers for early disease detection and therapeutic target identification, leading to improvements in patient care and clinical outcomes.214 Moreover, the ability of AI to analyze high-dimensional omics data has been crucial in pinpointing key features that influence disease progression and treatment response.215 The incorporation of EHRs with multiomics data provides additional context, enhancing the real-world relevance of research findings.129 The challenge of improving drug development efficiency against antibiotic-resistant bacteria has garnered significant attention.216 Barroso et al. combined proteomic analysis with shallow and DL models to screen and validate 20 promising candidates, introducing a novel approach to antibiotic development that substantially increases research efficiency.217 Feng et al. utilized structure-based drug design (SBDD) and modular synthesis to develop modified antimicrobial agents. Their lead compound, F8, displayed antimicrobial activity, with multiomics analysis (including transcriptomics, proteomics, and metabolomics) identifying ornithine carbamyltransferase (arcB) as a potential antimicrobial target. This integrated approach, which spans from drug screening to mechanistic research, significantly accelerates drug development timelines.218 The integration of AI and multiomics technologies has revolutionized drug development, addressing long-standing bottlenecks and enhancing the identification of novel drug targets and biomarkers. The following sections explore the applications of these technologies in drug development, focusing on three key therapeutic areas: nervous system drugs, antitumor drugs, and cardiovascular system drugs (Fig. 5).
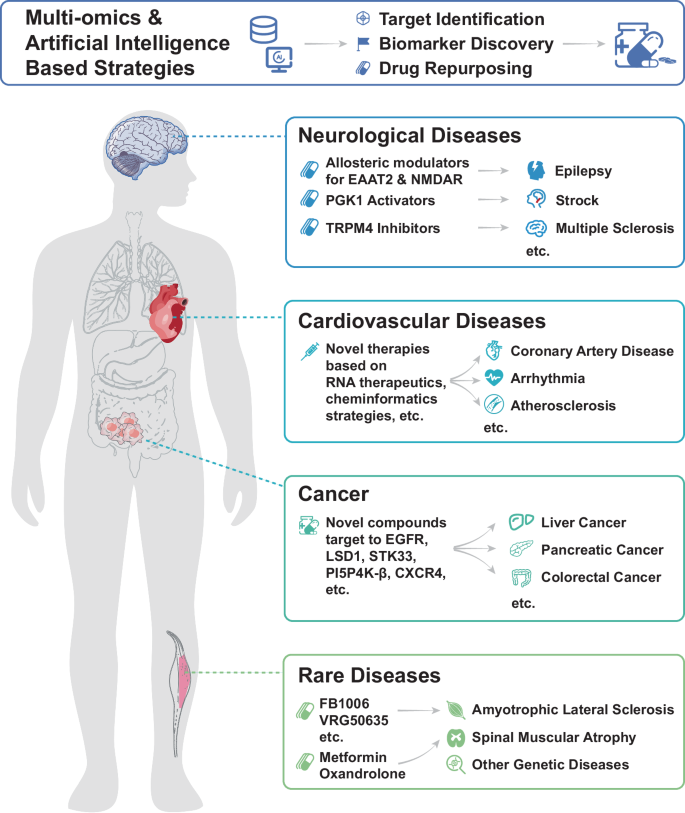
The alternative text for this image may have been generated using AI.
Full size image
Examples of drug development via multi-omics and artificial intelligence integration. Integration of multi-omics data and artificial intelligence enables comprehensive strategies for target identification, biomarker discovery, and drug repurposing. These approaches are applied across multiple disease categories, including neurological diseases, cardiovascular diseases, cancer, and some rare diseases
Development of drugs for treating neurological diseases
Drug repurposing offers significant advantages by reducing the time and cost associated with drug development, particularly for complex diseases such as neurological disorders. AI-integrated omics approaches are increasingly leveraged to predict disease risk factors. Research has shown that organ-specific aging disparities in living individuals can be quantified through human plasma protein levels. ML models analyzing aging across 11 major organs revealed that individuals with accelerated cardiac aging face a 2.5-fold greater risk of heart failure. In addition, accelerated brain and vascular aging independently predict AD progression, with predictive power comparable to that of plasma pTau-181, the current gold-standard blood-based biomarker for AD. AI-driven multiomics analyses have also linked vascular calcification, extracellular matrix alterations, and synaptic protein shedding to the early stages of cognitive decline.219,220 Moreover, the integration of multiomics and AI has accelerated the discovery of core targets in neurological diseases. While ischemic stroke is associated with imbalances in nucleotide metabolism, its key targets have remained elusive. Li et al. used LASSO regression, SVM-RFE, and RF algorithms to identify core immune-related genes. CIBERSORT analysis was employed to assess immune cell infiltration levels and their correlations. scRNA-seq data and molecular docking techniques were then applied to evaluate the gene expression patterns, subcellular localization, and gene-drug binding potential of CFL1, HMCES, and GIMAP1.221,222 Recent advancements in AI and deep learning technologies have enabled breakthroughs in de novo drug design and optimization. Techniques such as variational autoencoders, GANs, and normalizing flows have been harnessed to generate realistic, diverse molecules with drug-like properties and desirable brain-penetration characteristics. A collaborative international effort introduced GENTRL, a generative tensorial reinforcement-learning model for de novo small-molecule design. By optimizing synthetic accessibility, novelty, and bioactivity, GENTRL identified potent inhibitors of DDR1, a kinase target involved in fibrosis and neurodegeneration.143 In addition, DSP-0038—an AI-designed dual–target 5-HT1A agonist and 5-HT2A antagonist developed by Exscientia (UK)—has entered phase I trials as a potential treatment for AD-related psychosis.223 The convergence of AI and multiomics technologies has accelerated the identification of novel compounds for treating neurological disorders (Table 6). For example, EAAT2 (excitatory amino acid transporter 2), the main subtype responsible for glutamate clearance in the brain, plays a pivotal role in regulating neurotransmission and preventing excitotoxicity. Compounds that increase EAAT2 expression or activity hold significant neuroprotective potential. Kortagere et al. conducted virtual screening of a small-molecule library based on this molecular domain, identifying three compounds as activators and developing a high-resolution pharmacophore model.224 Drug retrosynthesis prediction has recently emerged as a critical technology in drug development. Once a desired molecular structure is identified, the next key question is whether it can be efficiently synthesized from existing compounds. Liu et al. approached retrosynthesis prediction as a machine-translation problem by encoding molecules as SMILES strings,225 whereas Shi et al. introduced a graph-to-graph framework, treating both product and reactant molecules as graphs.226 A newly reported chemical synthesis strategy termed “pharmacophore-directed retrosynthesis” has been used to produce the natural product gracilin A, which holds promise for treating neurodegenerative disorders such as AD. This approach of classifying diseases via multiomics and AI integration significantly enhances personalized treatment in precision medicine. Furthermore, Hu et al. demonstrated the clinical utility of multiomics/AI integration through consensus clustering of eight AD brain tissue datasets and three blood datasets, which revealed two molecularly distinct subtypes. Compared with Subtype B patients, Subtype A patients presented significantly increased γ-secretase activity, β-secretase activity, and amyloid-β42 levels, along with markedly elevated expression of druggable candidate genes—LIMK2, MAPK8, and NDUFV2—in both blood and brain tissues, establishing a precision medicine framework for personalized therapeutic intervention.227 According to the latest AD drug development pipeline (2023), 187 clinical trials are evaluating 141 drugs for AD treatment.228 To increase drug repurposing efforts, an ML-based framework called DRIAD was developed. DRIAD analyzes 80 FDA-approved and clinically tested drugs, induces perturbations in differentiated human nerve cell cultures, and generates a ranking of drug candidates for repurposing. The framework prioritized baricitinib as a promising candidate for AD,229 which is currently being tested in a clinical trial involving patients with both AD and amyotrophic lateral sclerosis (ALS) (ClinicalTrials.gov: NCT05189106).230 Another approach, the AlzGPS (Genome-wide Positioning Systems platform for Alzheimer’s Drug Discovery, https://alzgps.lerner.ccf.org), was created by Zhou et al. as a comprehensive systems biology tool that integrates over 100 AD-related omics datasets spanning DNA, RNA, protein, and small-molecule spectra. AlzGPS supports network visualizations, including brain-specific gene neighborhood networks, endophenic disease module networks, and drug mechanism-of-action networks for disease modules.231 Moreover, Xu et al. developed a DL approach, NETTAG, which integrates GWAS and multigenomic data to identify the pathobiology of AD and potential drug repurposing opportunities. Their study identified four drugs—ibuprofen, gefilozil, cholecalciferol, and ceftriaxone—that are associated with a reduced incidence of AD.231 Drug repurposing has become a pivotal strategy for enhancing therapeutic efficacy,232,233 exemplified by DeepDrug’s expansion of candidate targets to include longevity gene networks, immunosenescence pathways, and AD-associated somatic mutational signatures. This framework employs GNNs to encode biomedical knowledge graphs, incorporating heterogeneous biomedical relationships into low-dimensional manifolds that model internode dependencies across biological entities. Through systematic screening using diminishing-return thresholds, optimal high-order polypharmacology regimens can be identified. On the basis of the therapeutic synergy index of DeepDrug, a five-drug lead combination—comprising tofacitinib (JAK inhibitor), niraparib (PARP inhibitor), baricitinib (JAK1/2 inhibitor), empagliflozin (SGLT2 inhibitor), and doxercalciferol (vitamin D analog)—was prioritized to maximize synergistic efficacy against AD pathophysiology.234 According to the latest AD drug development pipeline (2023), approximately 50 repurposing trials are currently underway, which target approximately 40 distinct agents.228 To advance these repositioning efforts, the machine-learning framework DRIAD (Drug Repurposing in AD) was developed to quantify potential connections between AD-related biological processes and integrated genetic datasets, thereby prioritizing candidates for repurposing.229 DRIAD identified baricitinib as a leading AD candidate, which is now being evaluated in an open-label, biomarker-driven basket trial that includes patients with both AD and ALS (ClinicalTrials.gov: NCT05189106). Analysis of real-world insurance claims from 7.2 million patients in the IBM MarketScan Medicare Supplemental Database revealed that two FDA-approved p300/CBP inhibitors—salsalate and diflunisal—are associated with a reduced incidence of AD, with their neuroprotective efficacy validated in mouse models.235,236 Using an endophenotype-based computational network-medicine approach, another team reported that sildenafil use is significantly linked to a reduced likelihood of AD, a result that was later confirmed in neurons derived from induced pluripotent stem cells (iPSCs) of patients with AD.237 Furthermore, a separate study demonstrated that bumetanide, an FDA-approved oral diuretic, may serve as a potential therapeutic strategy for APOE4-associated AD.238 For migraine treatment, Sun et al. employed genetic data from MR, the FinnGen cohort, eQTLGen, and UKB-PPP, utilizing various analytical methods, including Bayesian colocalization, correlation heterogeneity tools (HEIDI), linkage disequilibrium score (LDSC), bidirectional magnetic resonance, multivariable magnetic resonance (MVMR), heterogeneity tests, horizontal pleiotropy tests, and Steiger filters, to consolidate their findings. Their drug predictive analysis and PheWAS identified GSTM4 as a promising therapeutic target for migraine treatment.239
Full size table
The integration of multiomics and AI can also be leveraged to predict neurotoxicity for various substances, including pharmaceutical compounds.240 Neurotoxic and nonneurotoxic drugs often exhibit distinct physicochemical properties, yet neurotoxicity datasets remain scarce. Commonly used predictive resources include SIDER and PubChem. Monzel et al. developed an RF model to predict neurotoxicity in brain organoids treated with 6-hydroxydopamine (6-OHDA) via image-based cytological analysis.241 They demonstrated RF’s effectiveness in predicting neurotoxic perturbations, incorporating variable importance evaluation and principal component analysis (PCA) to enhance model interpretability. Another study indicated that 2D models showed greater robustness under stringent genomic selection conditions, whereas 3D models experienced a notable decline in accuracy.242 Despite this, 3D organoid models better replicate authentic tissue microenvironments, and advancements in technology and algorithms are expected to further enhance predictions of drug-induced neurotoxicity. Identifying structural features associated with chemical neurotoxicity can facilitate the early-stage design of nontoxic compounds. Zhao et al. extracted drug neurotoxicity data from human clinical applications and constructed 35 distinct classifiers by combining five ML approaches with seven molecular fingerprints. Among these, the MACCS-SVM model delivered optimal performance.243 They identified 18 structural alerts linked to neurotoxicity and provided interpretable insights. Lee et al. proposed a peptide data augmentation strategy involving random substitution or insertion of arbitrary amino acids in known neurotoxic peptides to expand datasets and enhance neurotoxic peptide identification via CNNs.244 ImageMol is an unsupervised DL framework that is pretrained on ten million unlabeled drug-like bioactive molecular images to predict molecular targets and properties, including PK and PD. Across diverse benchmark datasets, ImageMol outperforms state-of-the-art methods.245 Recent advances in integrating ML with mechanistic modeling have resulted in a powerful toolkit for inferring the MoA, safety, efficacy, and PK/PD profile of candidate molecules.246 In AD drug development, poor BBB penetration is a significant contributor to high failure rates in clinical trials.247 To address this challenge, AI and ML models are now being used to predict BBB characteristics before experimental testing, a capability that can be directly applied to AD drug development programs.248,249
Development of antitumor drugs
The synergistic integration of multiomics data with AI frameworks has driven transformative advancements in precision oncology, particularly through paradigm-shifting applications in both solid and hematological malignancies. Large-scale tumor atlases generated by international consortia (e.g., TCGA and ICGC) utilize high-dimensional molecular profiling, including single-cell RNA sequencing, spatial proteomic mapping, and circulating tumor DNA methylation analysis, to construct predictive models of therapeutic response. These multidimensional datasets enable computational deconvolution of tumor ecosystems, facilitating research prioritization and clinical decision support through ML-driven biomarker discovery (Table 7). EGFR overexpression serves as an ideal target in anticancer drug development because of its absence in normal tissues. However, the development of drug resistance limits the therapeutic efficacy of currently approved EGFR inhibitors. An ML-based application has been proposed to predict the bioactivity of novel EGFR inhibitors, identifying N-substituted quinazolin-4-amine-based compounds as the largest cluster of EGFR inhibitors, with ~2500 compounds identified.250 The integration of multiomics and AI has significantly advanced the discovery of therapeutic targets and drugs for therapy-resistant malignancies.251 Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest malignancies, continues to have a five-year survival rate of less than 10%, despite current therapies. A multitiered systems biology and drug discovery pipeline was established, combining bulk genomics, single-cell spatial transcriptomics, proteomics, competitive endogenous RNA network analysis, and DL-driven QSAR modeling. This framework successfully predicted the TNFRSF10A-encoded TRAILR1 death receptor as a potential therapeutic target in PDAC and identified previously unexplored FDA-approved drugs and natural compounds—including temsirolimus, ergotamine, and capivasertib—demonstrating potential TRAILR1-modulating effects.252 Similarly, Yan et al. employed scRNA-seq and bulk RNA-seq data to analyze immunogenic cell death-related multiomics signatures in bladder cancer. They constructed a prognostic signature and explored its clinical and biological significance in terms of immune cell infiltration, tumor microenvironment characteristics, and therapeutic drug sensitivity. They discovered that the high-risk immunogenic cell death group exhibited resistance to cisplatin, mitomycin C, and paclitaxel, with significantly higher IC50 values than the low-risk group.253 Madhukar et al. applied this comprehensive approach to predict the targets and mechanisms of action of small anticancer molecules and demonstrated that integrating diverse data types improved the prediction accuracy.254 AI algorithms have also been applied to analyze multiomics data for identifying colorectal cancer subtypes, facilitating the development of more targeted and effective treatment strategies.255 Single-cell multiomics has proven valuable in identifying cellular hierarchies and lineage trajectories within tumors, including rare cancer stem cell populations responsible for tumorigenesis, progression, and relapse.256 This approach has also revealed the diverse roles of tumor-infiltrating immune cells, such as T cells and macrophages, in shaping the TME and influencing therapeutic responses.257 Recent single-cell analyses of glioblastoma have further elucidated the crosstalk between stromal cells, immune cells, and extracellular matrix components, leading to the discovery of novel therapeutic targets and biomarkers.258 The integration of spatial omics with AI has provided deeper insights into the spatial heterogeneity of the tumor microenvironment, enhancing our understanding of tumor behavior and responses to therapies.259 Spatial omics identifies intratumoral heterogeneity by mapping regions with distinct gene expression profiles, which are often linked to differential treatment responses.260 This approach also elucidates the interactions between cancer cells and surrounding stromal and immune cells, highlighting the importance of spatially organized cellular niches in tumor progression.261 These successes highlight the transformative potential of AI-driven multiomics analysis in revolutionizing patient management by providing a more comprehensive view of disease biology and facilitating the development of personalized therapies.262 Human epidermal growth factor receptor 2 (HER2)-targeted therapies show promise in treating HER2-amplified metastatic colorectal cancer; however, identifying the optimal biomarker for treatment decisions remains challenging. In the Exploratory Analysis of the Phase II TRIUMPH Trial, an AI-powered analysis was used to assess the ratio of tumor cells to HER2 staining intensity and tumor microenvironment cell density, exploring their associations with the clinical outcomes of TP. The study confirmed that AI-enhanced HER2 QCS and tumor microenvironment analysis could improve treatment response predictions for patients with HER2-amplified metastatic colorectal cancer undergoing TP therapy.263 In parallel, Kumar et al. developed a computational pipeline that uses pharmacogenomic data-driven optimization-regularization/greedy algorithms to predict novel therapeutics (“secDrugs”) for drug-resistant multiple myeloma. This approach integrates functional assays, including single-cell proteomics (CyTOF or flow cytometry time-of-flight), whole-genome transcriptome profiling (bulk RNA sequencing), and CRISPR-based gene editing, via ex vivo patient-derived bone marrow cells. These investigations systematically elucidated the molecular pathways underlying secDrug efficacy and drug synergism, suggesting innovative strategies to manage proteasome inhibitor- and immunomodulatory drug (IMiD)-resistant myeloma.264 Resistance to immunotherapy, driven by tumor heterogeneity, continues to be a significant challenge in cancer treatment. Quek et al., using Cite-seq and 40-plex phenocycler imaging, analyzed metastatic melanoma tumors through longitudinal multimodal monocyte tracking. Their analysis defined “immune combat” tumors as those with low lymphocyte infiltration around the tumor and reduced T-cell infiltration within the tumor. Recent advances in AI algorithms have increasingly integrated multiomics and radiomics, revealing complex patterns associated with cancer biology, prognosis, and treatment response. A study by Chen et al. demonstrated the potential of AI in predicting overall survival in non-small cell lung cancer patients by combining genomic data with radiomic features.265
Full size table
The integration of multiomics and AI is highly valuable for prognostic assessment in cancer. Posttreatment analysis of the MITF + SPARCL1+ and CENPF+ melanoma areas revealed insights into the molecular composition of microenvironmental cells and spatial structures, offering critical information for treatment interventions.266 Hu et al. developed an ensemble framework that integrates various ML and DL algorithms to establish a pyrimidine metabolism-related signature. Through comprehensive multiomics analyses evaluating its efficacy in terms of genomic stability, chemotherapy resistance, and immunotherapy resistance, they discovered that as pyrimidine metabolism-related signature scores increased, epithelial cells gradually acquired malignant phenotypes accompanied by increased pyrimidine metabolism. Patients with elevated pyrimidine metabolism-related signature scores exhibited a suppressive tumor immune microenvironment and poorer prognosis.267 Kan et al. analyzed real-world multiomics data from 400 patients with HR + /HER2- metastatic breast cancer treated with CDK4/6 inhibitors plus endocrine therapy. They constructed ML models to predict therapeutic vulnerabilities and reported that ER-dependent tumors rely on ESR1 and CDK4, whereas ER-independent tumors depend on CDK2. These findings were validated experimentally.268 In postmarketing pharmacovigilance, significant research efforts have been directed toward developing ML models for ADR prediction. By applying ML algorithms to oncology therapeutics, integrated phenotypic and transcriptomic data from physiologically relevant cardiac models—including human iPSC-derived cardiomyocytes and engineered heart tissues exposed to cardiotoxic compounds—have refined guidelines for structural cardiotoxicity assessment of chemotherapeutic agents. This approach enables the identification of targetable genetic signatures (e.g., TOP2B dysregulation and SLC28A3 polymorphisms) to guide subsequent targeted drug development.269,270 The multiscale drug safety evaluator (MSDSE) utilizes a hierarchical learning architecture that integrates multimodal features from local (molecular interactions) to global (population-level data) perspectives, effectively predicting clinical trial-emergent adverse events through GNN-based knowledge fusion.271 This pharmacogenomics-driven DL framework has demonstrated its unique ability to predict polypharmacy-induced ADRs via DDI network analysis, latent side-effects documented in the literature but absent from ground-truth databases, and off-target kinase inhibition profiles with 92.3% precision (AUC = 0.94).272 For predicting miRNA–drug sensitivity relationships, the novel graph collaborative filtering with multiview contrastive learning (GCFMCL) model represents the first computational framework to encode miRNA–mRNA regulatory networks as heterogeneous graphs, implement cross-view contrastive regularization between drug chemical structures and miRNA sequences, and identify hsa-miR-34a-mediated cisplatin resensitization in TP53-mutant NSCLC.273 Furthermore, DL applied to human multiomics datasets facilitates antibody optimization through structure-guided paratope refinement (affinity maturation ΔK = 0.8 nM), glycosylation pattern engineering to modulate FcγRIIIa binding, and developability profiling to predict aggregation hotspots.274 Multiomics-driven AI has proven instrumental in understanding drug resistance. A notable example is the development of PERCEPTION (PERsonalized Single-Cell Expression-Based Planning for Treatments in ONcology), a precision oncology computational pipeline that utilizes publicly available matched bulk-cell and single-cell expression profiles from large-scale cell line drug screenings. In two clinical trials involving multiple patients with myeloma, breast cancer, and lung cancer treated with tyrosine kinase inhibitors, this approach successfully predicted responses to targeted therapies in both cultured cells and primary cells derived from patient tumors.275
Development of drugs for treating cardiovascular diseases
CVD represents a complex condition in which environmental factors often play a more significant role than genetic predispositions do. Understanding CVD thus requires research across multiple biological levels.276,277 AI-assisted analysis of multiomics data can predict disease drug targets through genetic data, enabling cost-effective and robust analyses, even in studies lacking comprehensive multiomics datasets. With respect to target discovery, Xu et al. constructed a large cohort (INTERVAL, 50,000 participants) with extensive plasma proteomic multiomics data, including SomaScan (n = 3175), Olink (n = 4822), plasma metabolome HD4 (n = 8153), serum metabolomics (Nightingale, n = 37,359), and whole-blood Illumina RNA sequencing (n = 4136) data. ML was used to train genetic scores for 17,227 molecular traits, providing novel biological insights into the metabolic genetic mechanisms and pathways associated with CVD, such as JAK-STAT signaling and coronary atherosclerosis.278 Furthermore, Ouwerkerk et al. integrated genetic, transcriptomic, and proteomic data from a large cohort of patients with heart failure via an ML approach based on stacked generalization frameworks and gradient enhancement algorithms. This analysis identified four major pathways associated with mortality, including the reduced activation of the cardioprotective ERBB2 receptor, which can be modified by neuregulins.279 AI-driven processing of large-scale biological data significantly enhances the efficiency of data cleaning and analysis, advancing our understanding of CVD. The next frontier in CVD research lies in determining the biological function of the most influential sites, with the aim of uncovering novel therapeutic targets through insights derived from multiomics analyses. Yang et al. engineered an in vitro model of dilated cardiomyopathy using BAG3-deficient human iPSC-derived cardiomyocytes (hiPSC-CMs) combined with high-content phenotypic screening and DNN-based cheminformatics to identify cardioprotective compounds from 3872 bioactive agents. This integrated strategy accelerated drug discovery through DL-prioritized in vivo validation, with the lead candidate HDAC6 inhibitor ACY-1215 demonstrating (1) restored sarcomeric integrity (α-actinin striation index +0.41), (2) normalized calcium handling (Ca2+ transient amplitude ΔF/F₀ +29.7%), and (3) a 3.2-fold reduction in the preclinical development timeline.280 Following pretraining on 28 million single-cell transcriptomes, the Geneformer architecture achieved robust target prediction using limited external cohorts (n = 1500), with the model-nominated mTOR inhibitor everolimus showing significant functional improvement: 18.3% increase in fractional shortening, 52% reduction in collagen I deposition, and 37% enhancement in maximal mitochondrial respiratory capacity.281 Iborra-Egea et al.‘s multiomics temporal DL framework mapped postmyocardial infarction (MI) remodeling dynamics across three pathological phases: the acute phase (1–3 days: IGF1R ↑ /JUN↑ driving neutrophil extracellular trap formation), the subacute phase (7 days: RAF1 ↑ /KPCA↑ mediating myofibroblast transdifferentiation), and the chronic phase (28 days: PTPN11↑ promoting pathological hypertrophy). RAF1 inhibition attenuated ventricular wall thinning by 28% (P < 0.01). A novel dipeptide-encoded DL model utilizing a 256-bit binary feature representation achieved 99.2% external accuracy (AUROC = 0.998) in predicting antihypertensive peptides, successfully identifying potent ACE inhibitors (IC50 = 2.3 μM) that induced 82% vasodilation in aortic ring assays.282 ML has also facilitated precision drug repositioning, exemplified by the identification of metformin for heart failure via AMPK–PGC1α activation (ΔLVEF + 6.4%) and the use of rosiglitazone for myocardial protection through PPARγ-mediated NF-κB suppression.283 In coronary artery disease (CAD), a differentially expressed gene network was identified from peripheral blood samples of 66 patients and subsequently enriched via CARDIoGRAM284 and related consortia databases. The analysis revealed lipid metabolism and inflammatory signaling as key pathological mechanisms. Expression quantitative trait locus (eQTL) mapping further demonstrated that SNPs at 1p13 modulate the hepatic expression of SORT1, a gene that regulates plasma LDL levels.285,286 Informatics pipelines such as TopHat have proven effective in reducing error detection rates in such analyses.287,288 Emerging methods, including allele-specific expression modeling—quantifying the differential expression of maternal and paternal haplotypes—offer additional sensitivity, although their application in CVD research remains unexplored.289 The Starnet study adopted a similar multiomics strategy, integrating genotyping and RNA sequencing across six tissue types from 600 clinically profiled patients with CHD.290 Leveraging GWAS and gene regulation data, researchers have identified enriched cis-eQTLs and constructed overlapping causal networks specific to tissue type and disease context. Notably, SNPs modulating PCSK9 expression specifically in abdominal adipose tissue—but not in hepatic tissue—are associated with increased plasma LDL-cholesterol levels.291 This association holds clinical relevance given that PCSK9-targeting inhibitors, which act on this regulatory axis, have already been adopted in therapeutic practice.292
Validating drug efficacy at the target level constitutes a critical step in translational pharmacology, exemplified by the LRF-DTI approach. This method integrates multiple ML algorithms to predict drug–target interactions across diverse receptor classes—including enzymes, ion channels, G protein-coupled receptors, and nuclear receptors—and achieves an overall accuracy of 94.88%.283 Similarly, the DL model DEEPMPF constructs a heterogeneous network encompassing proteins, drugs, and diseases293 and employs joint learning to estimate interaction probabilities, yielding competitive performance in bioactive compound screening. Although such in silico strategies cannot yet supplant in vivo experimentation, their scalability and cost-effectiveness underscore their growing relevance in early-stage drug discovery. Large-scale phenotypic cohort studies such as STAGE and STARNET offer further translational value by integrating GWAS and cross-species data across multiple human tissues, addressing the cellular heterogeneity inherent to cardiovascular pathophysiology. The cardiovascular system comprises functionally distinct cell types, each of which differentially contributes to the omics landscape, necessitating tissue-specific analyses in CVD research. Systems biology approaches have been employed to simulate cellular and organellar functions in CVD, notably through genome-scale metabolic networks constructed from gene ontology annotations and curated experimental datasets.292 These networks, when applied to cardiomyocytes, have produced a cardiometabolic model encompassing 368 metabolic reactions and simulating perturbations in key metabolites such as glucose and fatty acids.294 Flux balance analysis has been used to model interactions among enzymes, metabolites, and cellular functions, identifying key reactions central to mitochondrial adaptation under hypoxic stress. These metabolic responses have been linked to SNPs enriched in high-altitude populations, offering insights into evolutionary adaptations to oxygen deprivation.295 In the clinical translation of AI, a novel predictive framework has been developed to assess phase III trial efficacy. ML models have been used to evaluate the therapeutic potential of 24 heart failure drugs across 266 phase III clinical trials, informing drug repurposing strategies for CVD treatment.296 For previously identified compounds or genetic targets, SVM neural networks have been used to predict the efficacy of three biomarkers—HBG1, SNCA, and GYPB—in stroke-associated atrial fibrillation. The Mayo–Baylor RIGHT 10 K study exemplifies the integration of genomics and DL in pharmacogenomics, applying AI to identify functionally deleterious variants in patients with clopidogrel-resistant atherosclerotic CVD. This enables individualized treatment strategies, including dosage optimization or alternative therapy selection, to improve clinical outcomes. Collectively, these AI-driven models enable cost-efficient large-scale drug repurposing and cohort stratification, offering substantial reductions in clinical trial expenditures and accelerating the path to therapeutic innovation.297
AI and multiomics technologies are not only significantly applied in drug development for diseases of the aforementioned three systems but also play important roles in diseases of the digestive system (such as diabetes), reproductive system, urinary system, and various rare diseases. Machine learning algorithms and multiomics have revealed that alterations in the microbiota, metabolites, and lipidomics profiles or functions are associated with diabetes patients.298 Allesøe et al. developed a deep learning-based framework to conduct multiomics phenotyping of 789 newly diagnosed type 2 diabetes patients from the DIRECT consortium. They successfully identified the 20 most prevalent pharmacogenomic associations in the multimodal datasets used for type 2 diabetes patients, with significantly higher sensitivity than univariate statistical tests. They also established a novel association between metformin and the gut microbiota, as well as the opposing molecular responses of two statins, simvastatin and atorvastatin, thereby expanding the therapeutic effects of diabetes medications.299 The potential of using artificial intelligence to create “digital twin” models that can rapidly conduct computer-based tests and determine dosages for personalized medicine.300 On the other hand, Si et al. designed a comprehensive analytical pipeline, including two-sample Mendelian randomization (MR) (for proteins), summary-based MR (SMR) (for mRNAs), and colocalization (for coding genes), to identify potential multiomics biomarkers for CKD. They identified 32 potential therapeutic targets for CKD, renal function, and specific CKD clinical subtypes, including GATM, AIF1L, DQA2, and PFKFB2.27 Multiomics studies have revealed key mechanisms driving ovarian aging, including defects in DNA damage and repair, inflammation, the immune response, mitochondrial dysfunction, and cell death. By leveraging AI to integrate multiomics data, researchers can identify key regulatory factors and mechanisms at different biological levels, thereby discovering potential therapeutic targets. These targets include genetic targets such as BRCA2 and TERT; epigenetic targets such as Tet and FTO; metabolic targets such as deacetylases and CD38 + ; protein targets such as BIN2 and PDGF-BB; and transcription factors such as FOXP1.301
Despite transformative progress in AI- and multiomics-enabled drug discovery, several structural bottlenecks persist that hinder widespread clinical translation and scalability.23,302 The key among these is data quality: although multiomics datasets offer high throughput and dimensionality, they are frequently compromised by noise, missing values, and batch effects, undermining data reliability. The inherent heterogeneity across omics layers—including genomics, transcriptomics, proteomics, and metabolomics—further complicates cross-modal integration owing to disparities in data formats, measurement standards, and biological scales.303 These limitations degrade the foundational inputs for AI model training and validation, resulting in issues such as algorithmic bias, limited generalizability, and misclassification of therapeutically elusive targets. Notably, AI models often struggle with predicting viable targets among intrinsically disordered proteins, transcription factors, and protein–protein interactions, which typically lack well-defined binding pockets and remain “undruggable” by conventional standards. This reflects a broader translational challenge: bridging the gap between mechanistic biological insights and clinically actionable therapeutics while concurrently embedding precision-delivery strategies. Compounding this issue, most AI algorithms in use today were originally developed for nonbiomedical domains and fail to address the intricate, nonlinear dynamics of biological systems. The high computational demands of training and deploying these models further dilute the expected cost savings. Additional systemic barriers include fragmented data-sharing infrastructures, inadequate population diversity in training datasets, and a lack of standardized protocols—all of which inflate frictional costs along the data-to-application continuum. Addressing these challenges requires a systems-level paradigm anchored in three pillars: data harmonization, algorithmic specialization, and translational convergence. Domain-informed data harmonization should prioritize the completeness, interoperability, and accessibility of multiomics datasets. Simultaneously, the development of bespoke algorithms optimized for biomedical contexts—paired with scalable, cost-efficient computational frameworks—can establish an end‒to-end translational pipeline that links target discovery, molecular engineering, and delivery platform design. This integrated approach is essential for realizing robust, generalizable, and clinically viable AI-driven drug discovery.
Integration of multi-omics and artificial intelligence facilitates precision drug clinical trial design
Clinical trials serve as the primary mechanism for evaluating the safety and efficacy of investigational drugs in human populations, typically spanning 6–7 years and demanding significant financial investment. Despite these efforts, only approximately 10% of investigational molecular entities receive regulatory approval, reflecting a high attrition rate across the industry.304 Common contributors to trial failure include inappropriate patient selection, inadequate infrastructure, and substandard site performance. AI offers solutions to many of these challenges by harnessing large-scale digital health data (Fig. 6).305 ML algorithms facilitate more efficient participant recruitment by mining historical trial datasets to identify suitable candidates. DL approaches further refine recruitment by ranking investigators on the basis of predicted enrollment performance, thereby improving site selection and operational efficiency.306 Given that patient enrollment consumes nearly one-third of the total trial duration, optimizing this phase is critical. Poor enrollment strategies account for approximately 86% of trials failing to yield meaningful outcomes.307 AI-driven review of patient-specific genomic and exposomic profiles enables the targeted selection of appropriate populations for Phase II and III trials, improving enrollment precision and trial efficacy.305,308 This targeted approach also supports early prediction of drug–target interactions within selected cohorts, increasing overall trial design. AI also facilitates adaptive trial designs, enabling real-time protocol adjustments in response to accumulated data, thereby optimizing resource utilization and increasing the probability of success.309 The integration of AI into trial management not only accelerates execution but also improves data robustness, ultimately expediting the drug development lifecycle.310 Predictive modeling and counterfactual reasoning algorithms can further enhance preclinical candidate evaluation by forecasting lead compound efficacy prior to trial initiation. This enables strategic alignment between molecular candidates and genetically appropriate patient subsets, as outlined in Table 8.305 Patient withdrawal remains a significant obstacle, accounting for roughly one-third of trial failures and often necessitating costly, time-consuming recruitment extensions. Ensuring participant adherence to study protocols is therefore essential.307 In response, AiCure deployed mobile software that uses computer vision to monitor medication adherence among patients with schizophrenia in a phase II trial. The application improved compliance by 25%, directly contributing to trial success.308 This example illustrates how digital health technologies can reinforce protocol adherence and improve trial outcomes. Moreover, the predictive capacity of AI was exemplified in IPF, where TNIK was identified as a therapeutic target. The resulting small-molecule inhibitor INS018_055 underwent successful in vivo validation and progressed to phase I clinical evaluation (NCT05154240, CTR20221542) within just 18 months—a compelling demonstration of the accelerated timelines achievable through generative AI-based drug discovery pipelines.142 Numerous pharmaceutical companies are actively investing in AI and maintaining strategic partnerships with AI providers to accelerate drug development. For example, Numerate, Inc. (San Francisco, CA 94107, USA) collaborated with Takeda Pharmaceutical Company to establish an AI-driven drug design platform focused on oncology and gastroenterology, culminating in the development of agent S48168, which is now in phase I clinical trials targeting ryanodine receptor 2.311 Similarly, Atomwise (San Francisco, CA 94103, USA) partnered with Eli Lilly and Company to develop AI-enabled structural modeling tools, leading to the advancement of the agent BBT-401, which is currently undergoing phase II clinical evaluation for a specific disease target. These collaborations underscore AI’s growing influence in streamlining drug discovery pipelines and highlight the translational potential of AI innovations within the pharmaceutical industry.312
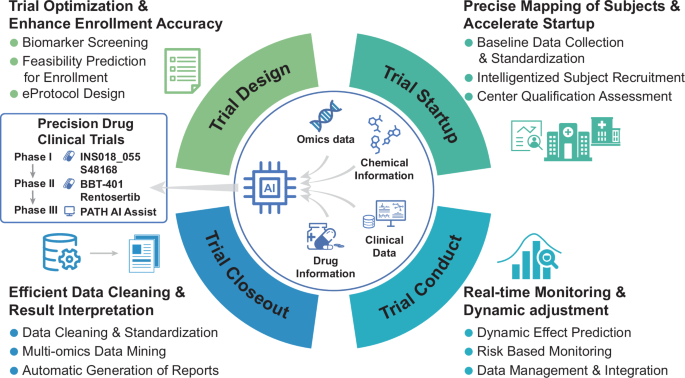
The alternative text for this image may have been generated using AI.
Full size image
Integration of multiomics and artificial intelligence facilitates precision drug clinical trial design. The integration of multiomics and artificial intelligence could facilitate clinical trials in the trial design, startup, conduction, and closeout stages
Full size table
Despite these advancements, integrating AI technologies into clinical trial workflows presents multifaceted challenges. Designing rational trial protocols and evaluating the safety–efficacy profiles of AI-informed therapeutics remain nontrivial tasks. DL models, in particular, suffer from limited interpretability, often functioning as “black boxes” with opaque reasoning pathways. This lack of transparency undermines clinical trust, posing barriers to the adoption of AI in high-stakes decision-making. In addition, the regulatory and ethical complexities surrounding AI–multiomics convergence—such as data privacy, model validation, and protocol compliance—demand robust governance structures and dedicated oversight frameworks. A 2024 BiopharmaTrend report illustrates these hurdles: among 31 AI-derived drug candidates from eight leading companies currently undergoing human trials, 17 remain in Phase I (one discontinued), five in Phase I/II (one terminated), and nine in Phases II/III (one reporting inconclusive results)—highlighting the uncertainty surrounding AI’s tangible impact on clinical progression.199,313 Nevertheless, the trajectory of AI in clinical research continues to expand, offering promising avenues for refining drug development strategies. Given the complex, heterogeneous nature of human disease, clinical trials require extensive multimodal datasets encompassing genomic, cellular, clinical, and behavioral variables.314,315 Disease heterogeneity is influenced by diverse factors, including age, sex, race, and ethnicity, necessitating inclusive trial designs that capture biological and sociocultural variability. Collaborative efforts across institutions must ensure equitable access, diverse enrollment, and representative datasets that reflect the full spectrum of patient populations.316 AI holds promise in advancing diversity in clinical trials by informing data-driven decision-making processes—such as assessing diagnostic accuracy across ethnic subgroups and predicting adverse events that may impact enrollment or retention. However, inherent biases within training datasets can propagate inequities, disproportionately affecting underrepresented populations.317 Mitigation strategies are being deployed to evaluate and correct bias in legacy datasets, whereas future model development will depend on the availability of demographically diverse training corpora. Achieving this goal will require coordinated efforts at local, national, and global scales. Initiatives such as the Global Biobank Meta-Analysis Initiative exemplify such cross-border cooperation, aiming to drive gene and target discovery while confronting racial disparities in health outcomes.318 Furthermore, large-scale, ethnically inclusive genetic studies have reshaped cognitive function research and informed pharmacological innovation.319
Conclusions and perspectives
The past decade has witnessed a transformative convergence of artificial intelligence and multiomics technologies, fundamentally redefining the paradigm of pharmaceutical discovery and development. This evolution marks a decisive shift away from reductionist, single-biomarker approaches towards holistic, systems-level investigations. Contemporary strategies now integrate spatiotemporal multiomic stratification, encompassing cutting-edge domains such as single-nucleus chromatin accessibility profiling, subcellular spatial proteomics, dynamic flux metabolomics, and longitudinal epigenome mapping. This paradigmatic shift is primarily propelled by concurrent advances in two key areas: sophisticated deep learning architectures—including graph neural networks and transformer models—and robust heterogeneous computing infrastructures. Together, these technological pillars enable the exascale processing of multimodal datasets and underpin three foundational transitions within the industry: (1) the replacement of single-target pharmacology with network-centric polypharmacology; (2) the substitution of linear development workflows with concurrent, iterative computational‒experimental cycles; and (3) the progression from population-averaged therapeutic regimens to individualized interventions guided by patient-specific digital twins.320,321 The synergistic integration of these modalities enhances causal target identification through advanced Bayesian network inference, facilitates de novo generative molecule design via 3D-conditioned variational autoencoders, and optimizes adaptive clinical trial designs using reinforcement learning frameworks (Fig. 7). Consequently, drug discovery is being transformed from a largely empirical, trial-and-error endeavor into a more predictive and engineered scientific discipline.
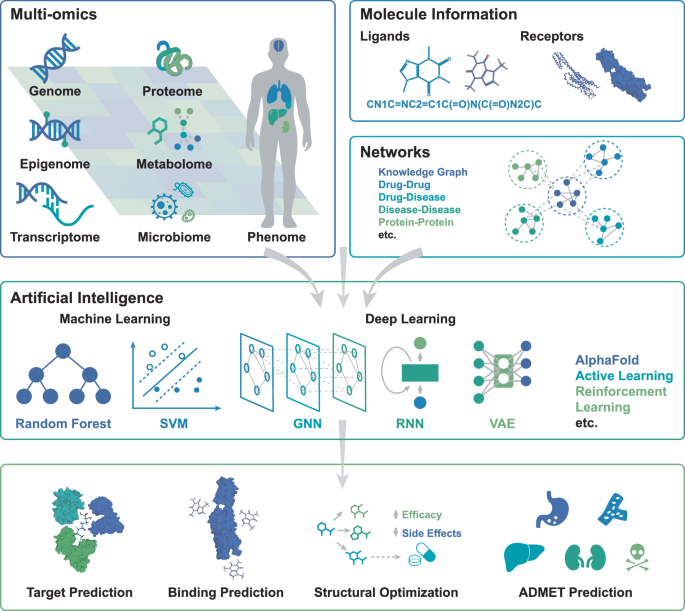
The alternative text for this image may have been generated using AI.
Full size image
Integration of multiomics and artificial intelligence facilitates drug discovery. SVM support vector machine, GNN graph neural network, RNN recurrent neural network, VAE variational autoencoder, ADMET absorption, distribution, metabolism, excretion, and toxicity
Despite this promising trajectory, significant challenges persist that threaten to impede full translational realization. Technical and Data Hurdles remain paramount. Inconsistent data normalization across diverse multiomic platforms creates integration artifacts, hampering the construction of unified biological models. Furthermore, the inherent “black-box” nature and interpretability limitations of many deep learning and deep reinforcement learning models pose substantial barriers to regulatory acceptance and clinical adoption. Perhaps most critically, a pronounced “translational gap” still exists between in silico predictions and tangible clinical outcomes. Ethical and Equity Dilemmas present a parallel set of concerns. Navigating the trade-off between maximizing data utility for research and upholding stringent privacy protections, such as those mandated by Genomic Data Commons policies, is an ongoing challenge. More alarmingly, issues of algorithmic justice demand urgent attention. The propagation and amplification of polygenic risk score miscalibrations, stemming from ancestrally biased training datasets, risk exacerbating existing healthcare disparities rather than alleviating them. Addressing these challenges is not optional but essential for the credible advancement of precision medicine.
To navigate these complexities and ensure sustainable progress, a multipronged strategy of coordinated innovation is required. Technologically, the development of privacy-preserving federated learning ecosystems is crucial for enabling secure, multi-institutional collaborative modeling compliant with regulations like HIPAA. The deliberate deployment of explainable AI techniques—such as counterfactual reasoning and concept activation vectors—is necessary to build transparency and trust in model outputs. To bridge the aforementioned translational gap, the implementation of human-relevant validation systems, notably organoid-based microphysiological platforms, will be vital for grounding computational predictions in human pathophysiology. From a governance and equity standpoint, the institutionalization of “equity-by-design” protocols must be mandated to ensure cohort diversity and proactive bias mitigation throughout the development pipeline. The demonstrated success of international consortia provides a blueprint for this collaborative approach. For instance, the MELLODDY project achieved a 40% improvement in predictive accuracy through secure multi-party computation, while the ATOM consortium reported a 63% reduction in preclinical attrition rates, validating the power of shared data and expertise.
Looking ahead, the full realization of this integrated AI-multiomics paradigm hinges on sustained investment in next-generation translational informatics infrastructure. This entails a long-term commitment to developing and adhering to FAIR (Findable, Accessible, Interoperable, Reusable) data ontologies, which are the bedrock of reproducible and collaborative science. Concurrently, establishing globally harmonized governance and ethical frameworks will be indispensable for managing the complex interplay of innovation, privacy, and equity. Ultimately, the goal is to catalyze a new wave of therapeutic innovation that is uniquely equipped to address two of modern medicine’s most daunting challenges: the profound complexity of human biology and the persistent scourge of structural health inequities. By systematically addressing the current limitations and steadfastly pursuing the outlined roadmap, the field can translate the vast potential of AI-driven multiomics into broadly accessible and effective precision therapies for patients worldwide.322
References
-
Minikel, E. V., Painter, J. L., Dong, C. C. & Nelson, M. R. Refining the impact of genetic evidence on clinical success. Nature 629, 624–629 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Ghosh, S. et al. Artificial intelligence applied to ‘omics data in liver disease: towards a personalised approach for diagnosis, prognosis and treatment. Gut 74, 295–311 (2025).
Article PubMed PubMed Central Google Scholar
-
He, X. et al. Artificial intelligence-based multi-omics analysis fuels cancer precision medicine. Semin. Cancer Biol. 88, 187–200 (2023).
Article CAS PubMed Google Scholar
-
Bessadok, A., Mahjoub, M. A. & Rekik, I. Graph neural networks in network neuroscience. IEEE Trans. Pattern Anal. Mach. Intell. 45, 5833–5848 (2023).
Article PubMed Google Scholar
-
He, X. H. et al. AlphaFold2 versus experimental structures: evaluation on G protein-coupled receptors. Acta Pharmacol. Sin. 44, 1–7 (2023).
Article CAS PubMed Google Scholar
-
Wenteler, A. et al. AI approaches for the discovery and validation of drug targets. Camb. Prism. Precis. Med. 2, e7 (2024).
Article PubMed PubMed Central Google Scholar
-
Shen, X. et al. Nonlinear dynamics of multi-omics profiles during human aging. Nat. Aging 4, 1619–1634 (2024).
Article PubMed PubMed Central Google Scholar
-
Hai, L., Jiang, Z., Zhang, H. & Sun, Y. From multi-omics to predictive biomarker: AI in tumor microenvironment. Front. Immunol. 15, 1514977 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Wu, Y. & Xie, L. AI-driven multi-omics integration for multi-scale predictive modeling of genotype-environment-phenotype relationships. Comput. Struct. Biotechnol. J. 27, 265–277 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Cui, H. et al. scGPT: toward building a foundation model for single-cell multi-omics using generative AI. Nat. Methods 21, 1470–1480 (2024).
Article CAS PubMed Google Scholar
-
Li, J. et al. Towards artificial intelligence to multi-omics characterization of tumor heterogeneity in esophageal cancer. Semin. Cancer Biol. 91, 35–49 (2023).
Article CAS PubMed Google Scholar
-
Giudice, V. et al. Aptamer-based proteomics of serum and plasma in acquired aplastic anemia. Exp. Hematol. 68, 38–50 (2018).
Article CAS PubMed PubMed Central Google Scholar
-
Saettini, F. et al. Biallelic PI4KA mutations disrupt B-cell metabolism and cause B-cell lymphopenia and hypogammaglobulinemia. J. Clin. Immunol. 45, 15 (2024).
Article PubMed Google Scholar
-
Li, W. et al. Multi-omics research strategies in ischemic stroke: a multidimensional perspective. Ageing Res. Rev. 81, 101730 (2022).
Article CAS PubMed Google Scholar
-
Yang, H. et al. From multi-omics data to the cancer druggable gene discovery: a novel machine learning-based approach. Brief. Bioinform. 24, bbac528 (2023).
-
Jiang, W., Ye, W., Tan, X. & Bao, Y. J. Network-based multi-omics integrative analysis methods in drug discovery: a systematic review. BioData Min. 18, 27 (2025).
Article PubMed PubMed Central Google Scholar
-
Zielinski, J. M., Luke, J. J., Guglietta, S. & Krieg, C. High Throughput multi-omics approaches for clinical trial evaluation and drug discovery. Front. Immunol. 12, 590742 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Leppä, A. M. et al. Single-cell multiomics analysis reveals dynamic clonal evolution and targetable phenotypes in acute myeloid leukemia with complex karyotype. Nat. Genet. 56, 2790–2803 (2024).
Article PubMed PubMed Central Google Scholar
-
Nishide, M. et al. Single-cell multi-omics analysis identifies two distinct phenotypes of newly-onset microscopic polyangiitis. Nat. Commun. 14, 5789 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Baalbaki, N. et al. The omics landscape of long COVID—a comprehensive systematic review to advance biomarker, target and drug discovery. Allergy 80, 932–948 (2025).
Article PubMed PubMed Central Google Scholar
-
Rasooly, D., Pereira, A. C. & Joseph, J. Drug discovery and development for heart failure using multi-omics approaches. Int. J. Mol. Sci. 26, 2703 (2025).
-
Pacini, C. et al. A comprehensive clinically informed map of dependencies in cancer cells and framework for target prioritization. Cancer Cell 42, 301–316.e309 (2024).
Article CAS PubMed Google Scholar
-
Bayat, A. et al. New insights into colorectal cancer through the lens of precision oncology and personalized medicine: multi-omics helps aging of predisposed people. Curr. Aging Sci. 18, 193–210 (2024).
Article Google Scholar
-
Chen, C. et al. Applications of multi-omics analysis in human diseases. MedComm 4, e315 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Bai, Y. et al. Identification of drug targets for Sjögren’s syndrome: multi-omics Mendelian randomization and colocalization analyses. Front. Immunol. 15, 1419363 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Huang, X. et al. Single-cell systems pharmacology identifies development-driven drug response and combination therapy in B cell acute lymphoblastic leukemia. Cancer Cell 42, 552–567.e556 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Si, S., Liu, H., Xu, L. & Zhan, S. Identification of novel therapeutic targets for chronic kidney disease and kidney function by integrating multi-omics proteome with transcriptome. Genome Med. 16, 84 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Mondal, R. et al. Applications of clustered regularly interspaced short palindromic repeats (CRISPR) as a genetic scalpel for the treatment of cancer: a translational narrative review. Cureus 15, e50031 (2023).
PubMed PubMed Central Google Scholar
-
Kampmann, M. CRISPR-based functional genomics for neurological disease. Nat. Rev. Neurol. 16, 465–480 (2020).
Article PubMed PubMed Central Google Scholar
-
MacLeod, G. et al. Genome-wide CRISPR-Cas9 screens expose genetic vulnerabilities and mechanisms of temozolomide sensitivity in glioblastoma stem cells. Cell Rep. 27, 971–986.e979 (2019).
Article CAS PubMed Google Scholar
-
McLean, B. et al. A CRISPR path to finding vulnerabilities and solving drug resistance: targeting the diverse cancer landscape and its ecosystem. Adv. Genet. 3, 2200014 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Jin, Y. et al. Application and progress of CRISPR/Cas9 gene editing in B-cell lymphoma: a narrative review. Transl. Cancer Res. 13, 1584–1595 (2024).
Article PubMed PubMed Central Google Scholar
-
Katti, A. et al. CRISPR in cancer biology and therapy. Nat. Rev. Cancer 22, 259–279 (2022).
Article CAS PubMed Google Scholar
-
Xu, Z. et al. Structural variants drive context-dependent oncogene activation in cancer. Nature 612, 564–572 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Bian, S. et al. Genetically engineered cerebral organoids model brain tumor formation. Nat. Methods 15, 631–639 (2018).
Article CAS PubMed PubMed Central Google Scholar
-
Li, S., Zhang, Z. & Han, L. 3D spheroids propel tumor characterization. Trends Cancer 6, 622–624 (2020).
Article CAS PubMed Google Scholar
-
Goodwin, R. J. A., Platz, S. J., Reis-Filho, J. S. & Barry, S. T. Accelerating drug development using spatial multi-omics. Cancer Discov. 14, 620–624 (2024).
Article CAS PubMed Google Scholar
-
Tang, W. H. W. & Koenig, W. Multiomics insights to accelerate drug development: will they hold their promises? J. Am. Coll. Cardiol. 82, 1932–1935 (2023).
Article CAS PubMed Google Scholar
-
Wang, F. & Barrero, C. A. Multi-omics analysis identified drug repurposing targets for chronic obstructive pulmonary disease. Int. J. Mol. Sci. 25, 11106 (2024).
-
Zhao, Y. et al. Diverse alterations associated with resistance to KRAS(G12C) inhibition. Nature 599, 679–683 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Fujino, T. et al. Sensitivity and resistance of MET exon 14 mutations in lung cancer to eight MET tyrosine kinase inhibitors in vitro. J. Thorac. Oncol. 14, 1753–1765 (2019).
Article CAS PubMed Google Scholar
-
Baechler, S. A. et al. The mitochondrial type IB topoisomerase drives mitochondrial translation and carcinogenesis. Nat. Commun. 10, 83 (2019).
Article CAS PubMed PubMed Central Google Scholar
-
Zhao, H. et al. APC/C-regulated CPT1C promotes tumor progression by upregulating the energy supply and accelerating the G1/S transition. Cell Commun. Signal 22, 283 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Servetto, A., Formisano, L. & Arteaga, C. L. FGFR signaling and endocrine resistance in breast cancer: challenges for the clinical development of FGFR inhibitors. Biochim Biophys. Acta Rev. Cancer 1876, 188595 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Du, P. et al. Advances in integrated multi-omics analysis for drug-target identification. Biomolecules. 14, 692 (2024).
-
Zhu, Q. et al. Single cell multi-omics reveal intra-cell-line heterogeneity across human cancer cell lines. Nat. Commun. 14, 8170 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Liang, W. et al. An integrated multi-omics analysis reveals osteokines involved in global regulation. Cell Metab. 36, 1144–1163.e1147 (2024).
Article CAS PubMed Google Scholar
-
Li, Y. et al. Unraveling the spatial organization and development of human thymocytes through integration of spatial transcriptomics and single-cell multi-omics profiling. Nat. Commun. 15, 7784 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Vandereyken, K., Sifrim, A., Thienpont, B. & Voet, T. Methods and applications for single-cell and spatial multi-omics. Nat. Rev. Genet. 24, 494–515 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Baysoy, A., Bai, Z., Satija, R. & Fan, R. The technological landscape and applications of single-cell multi-omics. Nat. Rev. Mol. Cell Biol. 24, 695–713 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Takei, Y. et al. Spatial multi-omics reveals cell-type-specific nuclear compartments. Nature 641, 1037–1047 (2025).
Article CAS PubMed Google Scholar
-
Liu, X. et al. Spatial multi-omics: deciphering technological landscape of integration of multi-omics and its applications. J. Hematol. Oncol. 17, 72 (2024).
Article PubMed PubMed Central Google Scholar
-
Sun, C. et al. Spatially resolved multi-omics highlights cell-specific metabolic remodeling and interactions in gastric cancer. Nat. Commun. 14, 2692 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Liu, Y. et al. Conserved spatial subtypes and cellular neighborhoods of cancer-associated fibroblasts revealed by single-cell spatial multi-omics. Cancer Cell 43, 905–924.e906 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Hsieh, W. C. et al. Spatial multi-omics analyses of the tumor immune microenvironment. J. Biomed. Sci. 29, 96 (2022).
Article PubMed PubMed Central Google Scholar
-
Qin, Y. et al. Cuproptosis correlates with immunosuppressive tumor microenvironment based on pan-cancer multiomics and single-cell sequencing analysis. Mol. Cancer 22, 59 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Mars, R. A. T. et al. Longitudinal multi-omics reveals subset-specific mechanisms underlying irritable bowel syndrome. Cell 182, 1460–1473.e1417 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Zhang, Q. et al. Implications of gut microbiota-mediated epigenetic modifications in intestinal diseases. Gut Microbes 17, 2508426 (2025).
Article PubMed PubMed Central Google Scholar
-
Zou, F. et al. Effects of short-chain fatty acids in inhibiting HDAC and activating p38 MAPK are critical for promoting B10 cell generation and function. Cell Death Dis. 12, 582 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Donohoe, D. R. et al. A gnotobiotic mouse model demonstrates that dietary fiber protects against colorectal tumorigenesis in a microbiota- and butyrate-dependent manner. Cancer Discov. 4, 1387–1397 (2014).
Article CAS PubMed PubMed Central Google Scholar
-
Sanchez, H. N. et al. B cell-intrinsic epigenetic modulation of antibody responses by dietary fiber-derived short-chain fatty acids. Nat. Commun. 11, 60 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Bendixen, L., Jensen, T. I. & Bak, R. O. CRISPR-Cas-mediated transcriptional modulation: the therapeutic promises of CRISPRa and CRISPRi. Mol. Ther. 31, 1920–1937 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
de Bakker, V., Liu, X., Bravo, A. M. & Veening, J. W. CRISPRi-seq for genome-wide fitness quantification in bacteria. Nat. Protoc. 17, 252–281 (2022).
Article PubMed Google Scholar
-
Santinha, A. J. et al. Transcriptional linkage analysis with in vivo AAV-Perturb-seq. Nature 622, 367–375 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Replogle, J. M. et al. Mapping information-rich genotype-phenotype landscapes with genome-scale Perturb-seq. Cell 185, 2559–2575.e2528 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Hou, J. et al. Integrated multi-omics analyses identify anti-viral host factors and pathways controlling SARS-CoV-2 infection. Nat. Commun. 15, 109 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Chen, L. et al. Refining antipsychotic treatment strategies in schizophrenia: discovery of genetic biomarkers for enhanced drug response prediction. Mol. Psychiatry 30, 2362–2371 (2025).
Article CAS PubMed Google Scholar
-
Heffel, M. G. et al. Temporally distinct 3D multi-omic dynamics in the developing human brain. Nature 635, 481–489 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Richetto, J. & Meyer, U. Epigenetic modifications in schizophrenia and related disorders: molecular scars of environmental exposures and source of phenotypic variability. Biol. Psychiatry 89, 215–226 (2021).
Article CAS PubMed Google Scholar
-
Guo, L. K. et al. Prediction of treatment response to antipsychotic drugs for precision medicine approach to schizophrenia: randomized trials and multiomics analysis. Mil. Med. Res. 10, 24 (2023).
CAS PubMed PubMed Central Google Scholar
-
Yang, W., Liu, C., Li, Z. & Cui, M. Multi-omic biomarkers associated with multiple sclerosis: from Mendelian randomization to drug prediction. Sci. Rep. 15, 9421 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Han, Q. J. et al. PTGES2 and RNASET2 identified as novel potential biomarkers and therapeutic targets for basal cell carcinoma: insights from proteome-wide mendelian randomization, colocalization, and MR-PheWAS analyses. Front. Pharmacol. 15, 1418560 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Xie, J. et al. Identification of genetic association between mitochondrial dysfunction and knee osteoarthritis through integrating multi-omics: a summary data-based Mendelian randomization study. Clin. Rheumatol. 43, 3487–3496 (2024).
Article PubMed PubMed Central Google Scholar
-
Shi, K. et al. Identification of potential therapeutic targets for nonischemic cardiomyopathy in European ancestry: an integrated multiomics analysis. Cardiovasc. Diabetol. 23, 338 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Rapicavoli, R. V., Alaimo, S., Ferro, A. & Pulvirenti, A. Computational methods for drug repurposing. Adv. Exp. Med. Biol. 1361, 119–141 (2022).
Article CAS PubMed Google Scholar
-
Aldea, M. et al. Precision medicine in the era of multi-omics: can the data tsunami guide rational treatment decision? ESMO Open 8, 101642 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Lee, S. Y. et al. A proteotranscriptomic-based computational drug-repositioning method for Alzheimer’s disease. Front. Pharmacol. 10, 1653 (2019).
Article CAS PubMed Google Scholar
-
Xu, J. et al. Interpretable deep learning translation of GWAS and multi-omics findings to identify pathobiology and drug repurposing in Alzheimer’s disease. Cell Rep. 41, 111717 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Albuquerque, A. M. et al. Effect of tocilizumab, sarilumab, and baricitinib on mortality among patients hospitalized for COVID-19 treated with corticosteroids: a systematic review and meta-analysis. Clin. Microbiol Infect. 29, 13–21 (2023).
Article CAS PubMed Google Scholar
-
Karampitsakos, T. et al. Tocilizumab versus baricitinib in hospitalized patients with severe COVID-19: an open label, randomized controlled trial. Clin. Microbiol. Infect. 29, 372–378 (2023).
Article CAS PubMed Google Scholar
-
Guo, H. et al. Multi-omics analyses reveal that HIV-1 alters CD4(+) T cell immunometabolism to fuel virus replication. Nat. Immunol. 22, 423–433 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Zhou, S. et al. Potential anti-liver cancer targets and mechanisms of kaempferitrin based on network pharmacology, molecular docking and experimental verification. Comput. Biol. Med. 178, 108693 (2024).
Article CAS PubMed Google Scholar
-
Nguyen, T. M. et al. DeCoST: a new approach in drug repurposing from control system theory. Front. Pharmacol. 9, 583 (2018).
Article PubMed PubMed Central Google Scholar
-
Li, X. et al. Network pharmacology approaches for research of traditional Chinese medicines. Chin. J. Nat. Med. 21, 323–332 (2023).
PubMed Google Scholar
-
Yang, S. et al. Integrated bioinformatics and multiomics reveal Liupao tea extract alleviating NAFLD via regulating hepatic lipid metabolism and gut microbiota. Phytomedicine 132, 155834 (2024).
Article CAS PubMed Google Scholar
-
Ye, J. et al. Multi-omics and network pharmacology study reveals the effects of Dengzhan Shengmai capsule against neuroinflammatory injury and thrombosis induced by ischemic stroke. J. Ethnopharmacol. 305, 116092 (2023).
Article CAS PubMed Google Scholar
-
Mokou, M. et al. A drug repurposing pipeline based on bladder cancer integrated proteotranscriptomics signatures. Methods Mol. Biol. 2684, 59–99 (2023).
Article CAS PubMed Google Scholar
-
Timilsina, S. et al. The antidepressant imipramine inhibits breast cancer growth by targeting estrogen receptor signaling and DNA repair events. Cancer Lett. 540, 215717 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Kandela, I. & Aird, F. Replication study: discovery and preclinical validation of drug indications using compendia of public gene expression data. eLife 6, e17044 (2017).
Article PubMed PubMed Central Google Scholar
-
Lee, S. et al. High-throughput identification of repurposable neuroactive drugs with potent anti-glioblastoma activity. Nat. Med. 30, 3196–3208 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Daher, A. & de Groot, J. Rapid identification and validation of novel targeted approaches for glioblastoma: a combined ex vivo-in vivo pharmaco-omic model. Exp. Neurol. 299, 281–288 (2018).
Article CAS PubMed Google Scholar
-
Dudley, J. T. et al. Computational repositioning of the anticonvulsant topiramate for inflammatory bowel disease. Sci. Transl. Med. 3, 96ra76 (2011).
Article CAS PubMed PubMed Central Google Scholar
-
Aydin, B. et al. Epigenomic and transcriptomic landscaping unraveled candidate repositioned therapeutics for non-functioning pituitary neuroendocrine tumors. J. Endocrinol. Invest. 46, 727–747 (2023).
Article CAS PubMed Google Scholar
-
Boso, D. et al. Anti-VEGF therapy selects for clones resistant to glucose starvation in ovarian cancer xenografts. J. Exp. Clin. Cancer Res. 42, 196 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Liu, Y. et al. High-spatial-resolution multi-omics sequencing via deterministic barcoding in tissue. Cell 183, 1665–1681.e1618 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Miller, B. F. et al. Reference-free cell type deconvolution of multi-cellular pixel-resolution spatially resolved transcriptomics data. Nat. Commun. 13, 2339 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Zhang, S. L. et al. Acarbose enhances the efficacy of immunotherapy against solid tumours by modulating the gut microbiota. Nat. Metab. 6, 1991–2009 (2024).
Article CAS PubMed Google Scholar
-
Mayor-Ruiz, C. et al. Rational discovery of molecular glue degraders via scalable chemical profiling. Nat. Chem. Biol. 16, 1199–1207 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Pan, S. et al. Metabolomics-driven approaches for identifying therapeutic targets in drug discovery. MedComm 5, e792 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Serral, F. et al. From genome to drugs: new approaches in antimicrobial discovery. Front. Pharmacol. 12, 647060 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Zhong-gen, Z. Advances in biosynthesis and regulation of the active ingredient of Salvia miltiorrhiza based on multi-omics approach. Acta Pharm. Sin. 55(12), 2892–2903 (2020).
Google Scholar
-
Yuan, Z. et al. Celastrol combats methicillin-resistant Staphylococcus aureus by targeting Δ(1) -pyrroline-5-carboxylate dehydrogenase. Adv. Sci. 10, e2302459 (2023).
Article Google Scholar
-
Soares, N. C. et al. Unveiling the mechanism of action of nature-inspired anti-cancer compounds using a multi-omics approach. J. Proteom. 265, 104660 (2022).
Article CAS Google Scholar
-
Wu, L. et al. Glycyrrhiza, a commonly used medicinal herb: review of species classification, pharmacology, active ingredient biosynthesis, and synthetic biology. J. Adv. Res. 75, 249–270 (2024).
Article PubMed PubMed Central Google Scholar
-
Wang, Y., Shi, Y. N., Xiang, H. & Shi, Y. M. Exploring nature’s battlefield: organismic interactions in the discovery of bioactive natural products. Nat. Prod. Rep. 41, 1630–1651 (2024).
Article CAS PubMed Google Scholar
-
Palazzotto, E., Tong, Y., Lee, S. Y. & Weber, T. Synthetic biology and metabolic engineering of actinomycetes for natural product discovery. Biotechnol. Adv. 37, 107366 (2019).
Article CAS PubMed Google Scholar
-
Ding, X. et al. Multiple mitochondria-targeted components screened from Sini decoction improved cardiac energetics and mitochondrial dysfunction to attenuate doxorubicin-induced cardiomyopathy. Theranostics 13, 510–530 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Ma, C. et al. Qijiao Shengbai Capsule alleviated leukopenia by interfering leukotriene pathway: integrated network study of multi-omics. Phytomedicine 128, 155424 (2024).
Article CAS PubMed Google Scholar
-
Cheng, L. et al. The protective role of commensal gut microbes and their metabolites against bacterial pathogens. Gut Microbes 16, 2356275 (2024).
Article PubMed PubMed Central Google Scholar
-
Castelo, J. et al. The microbiota metabolite, phloroglucinol, confers long-term protection against inflammation. Gut Microbes 16, 2438829 (2024).
Article PubMed PubMed Central Google Scholar
-
Liu, J. R. et al. Gut microbiota-derived tryptophan metabolism mediates renal fibrosis by aryl hydrocarbon receptor signaling activation. Cell Mol. Life Sci. 78, 909–922 (2021).
Article CAS PubMed Google Scholar
-
Vogel, C. F. A., Van Winkle, L. S., Esser, C. & Haarmann-Stemmann, T. The aryl hydrocarbon receptor as a target of environmental stressors— implications for pollution mediated stress and inflammatory responses. Redox Biol. 34, 101530 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Liu, N. N. et al. Multi-kingdom microbiota analyses identify bacterial-fungal interactions and biomarkers of colorectal cancer across cohorts. Nat. Microbiol 7, 238–250 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Gao, W. et al. Multimodal metagenomic analysis reveals microbial single nucleotide variants as superior biomarkers for early detection of colorectal cancer. Gut Microbes 15, 2245562 (2023).
Article PubMed PubMed Central Google Scholar
-
Ma, A., Xin, G. & Ma, Q. The use of single-cell multi-omics in immuno-oncology. Nat. Commun. 13, 2728 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Collora, J. A. et al. Single-cell multiomics reveals persistence of HIV-1 in expanded cytotoxic T cell clones. Immunity 55, 1013–1031.e1017 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Rausch, J. W. et al. HIV expression in infected T cell clones. Viruses 16, 108 (2024).
-
Unterman, A. et al. Single-cell multi-omics reveals dyssynchrony of the innate and adaptive immune system in progressive COVID-19. Nat. Commun. 13, 440 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Anglada-Girotto, M. et al. Combining CRISPRi and metabolomics for functional annotation of compound libraries. Nat. Chem. Biol. 18, 482–491 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Mitchell, D. C. et al. A proteome-wide atlas of drug mechanism of action. Nat. Biotechnol. 41, 845–857 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Yang, C. et al. Mendelian randomization and genetic colocalization infer the effects of the multi-tissue proteome on 211 complex disease-related phenotypes. Genome Med. 14, 140 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Chen, P. et al. Integrated spatial metabolomics and transcriptomics decipher the hepatoprotection mechanisms of wedelolactone and demethylwedelolactone on non-alcoholic fatty liver disease. J. Pharm. Anal. 14, 100910 (2024).
Article PubMed Google Scholar
-
Ji, S. et al. Pharmaco-proteogenomic characterization of liver cancer organoids for precision oncology. Sci. Transl. Med. 15, eadg3358 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Waldenmaier, H. E. et al. “Lab of the future”─today: fully automated system for high-throughput mass spectrometry analysis of biotherapeutics. J. Am. Soc. Mass Spectrom. 34, 1073–1085 (2023).
Article CAS PubMed Google Scholar
-
Howard, J. & Reiber, J. H. C. Automated analysis of coronary angiograms using artificial intelligence: a window into the cath lab of the future. EuroIntervention 17, 16–17 (2021).
Article PubMed PubMed Central Google Scholar
-
Xiong, Z. et al. Facing small and biased data dilemma in drug discovery with enhanced federated learning approaches. Sci. China Life Sci. 65, 529–539 (2022).
Article PubMed Google Scholar
-
Xiong, G. et al. ADMETlab 2.0: an integrated online platform for accurate and comprehensive predictions of ADMET properties. Nucleic Acids Res. 49, W5–w14 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Qiao, J. et al. AI-based R&D for frozen and thawed meat: research progress and future prospects. Compr. Rev. Food Sci. Food Saf. 23, e70016 (2024).
Article PubMed Google Scholar
-
Tong, L. et al. Integrating multi-omics data with EHR for precision medicine using advanced artificial intelligence. IEEE Rev. Biomed. Eng. 17, 80–97 (2024).
Article PubMed Google Scholar
-
Yang, Z., Guan, F., Bronk, L. & Zhao, L. Multi-omics approaches for biomarker discovery in predicting the response of esophageal cancer to neoadjuvant therapy: a multidimensional perspective. Pharm. Ther. 254, 108591 (2024).
Article CAS Google Scholar
-
Li, L., Sun, M., Wang, J. & Wan, S. Multi-omics based artificial intelligence for cancer research. Adv. Cancer Res. 163, 303–356 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Qiu, Y. & Cheng, F. Artificial intelligence for drug discovery and development in Alzheimer’s disease. Curr. Opin. Struct. Biol. 85, 102776 (2024).
Article CAS PubMed Google Scholar
-
Choi, S., Adams, A. M. & Chibale, K. Special issue: exploring the use of AI/ML technologies in medicinal chemistry and drug discovery. ACS Med. Chem. Lett. 16, 174 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Sumathi, S. et al. A review on deep learning-driven drug discovery: strategies, tools and applications. Curr. Pharm. Des. 29, 1013–1025 (2023).
Article CAS PubMed Google Scholar
-
Gangwal, A. et al. Generative artificial intelligence in drug discovery: basic framework, recent advances, challenges, and opportunities. Front. Pharmacol. 15, 1331062 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Stokes, J. M. et al. A deep learning approach to antibiotic discovery. Cell 180, 688–702.e613 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Liu, G. et al. Deep learning-guided discovery of an antibiotic targeting Acinetobacter baumannii. Nat. Chem. Biol. 19, 1342–1350 (2023).
Article CAS PubMed Google Scholar
-
Yang, K. et al. Analyzing learned molecular representations for property prediction. J. Chem. Inf. Model. 59, 3370–3388 (2019).
Article CAS PubMed PubMed Central Google Scholar
-
Luttens, A. et al. Rapid traversal of vast chemical space using machine learning-guided docking screens. Nat. Comput. Sci. 5, 301–312 (2025).
Article PubMed PubMed Central Google Scholar
-
Patronov, A., Papadopoulos, K. & Engkvist, O. Has artificial intelligence impacted drug discovery? Methods Mol. Biol. 2390, 153–176 (2022).
Article CAS PubMed Google Scholar
-
Vamathevan, J. et al. Applications of machine learning in drug discovery and development. Nat. Rev. Drug Discov. 18, 463–477 (2019).
Article CAS PubMed PubMed Central Google Scholar
-
Ren, F. et al. A small-molecule TNIK inhibitor targets fibrosis in preclinical and clinical models. Nat. Biotechnol. 43, 63–75 (2025).
Article CAS PubMed Google Scholar
-
Zhavoronkov, A. et al. Deep learning enables rapid identification of potent DDR1 kinase inhibitors. Nat. Biotechnol. 37, 1038–1040 (2019).
Article CAS PubMed Google Scholar
-
Li, X. S. et al. Multiphysical graph neural network (MP-GNN) for COVID-19 drug design. Brief. Bioinform. 23, bbac231 (2022).
-
Wong, F. et al. An explainable deep learning platform for molecular discovery. Nat. Protoc. 20, 1020–1056 (2025).
Article CAS PubMed Google Scholar
-
Fotis, C., Meimetis, N., Sardis, A. & Alexopoulos, L. G. DeepSIBA: chemical structure-based inference of biological alterations using deep learning. Mol. Omics 17, 108–120 (2021).
Article CAS PubMed Google Scholar
-
Liu, G. & Stokes, J. M. A brief guide to machine learning for antibiotic discovery. Curr. Opin. Microbiol. 69, 102190 (2022).
Article CAS PubMed Google Scholar
-
Wong, F. et al. Discovery of a structural class of antibiotics with explainable deep learning. Nature 626, 177–185 (2024).
Article CAS PubMed Google Scholar
-
Zhan, H., Zhu, X., Qiao, Z. & Hu, J. Graph neural tree: a novel and interpretable deep learning-based framework for accurate molecular property predictions. Anal. Chim. Acta 1244, 340558 (2023).
Article CAS PubMed Google Scholar
-
Deng, D. et al. XGraphBoost: extracting graph neural network-based features for a better prediction of molecular properties. J. Chem. Inf. Model. 61, 2697–2705 (2021).
Article CAS PubMed Google Scholar
-
Olivecrona, M., Blaschke, T., Engkvist, O. & Chen, H. Molecular de-novo design through deep reinforcement learning. J. Cheminform. 9, 48 (2017).
Article PubMed PubMed Central Google Scholar
-
Maziarka, Ł et al. Mol-CycleGAN: a generative model for molecular optimization. J. Cheminform. 12, 2 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Tu, X. et al. Artificial intelligence-enabled discovery of a RIPK3 inhibitor with neuroprotective effects in an acute glaucoma mouse model. Chin. Med. J. 138, 172–184 (2025).
Article CAS PubMed Google Scholar
-
Wang, N., Dong, J. & Ouyang, D. AI-directed formulation strategy design initiates rational drug development. J. Control. Release 378, 619–636 (2025).
Article CAS PubMed Google Scholar
-
Gold, E. R. & Cook-Deegan, R. AI drug development’s data problem. Science 388, 131 (2025).
Article PubMed Google Scholar
-
Cyranoski, D. AI drug discovery booms in China. Nat. Biotechnol. 39, 900–902 (2021).
Article CAS PubMed Google Scholar
-
Wang, Y., Yang, Z. & Yao, Q. Accurate and interpretable drug-drug interaction prediction enabled by knowledge subgraph learning. Commun. Med. 4, 59 (2024).
Article PubMed PubMed Central Google Scholar
-
Zhang, Y. et al. Emerging drug interaction prediction enabled by a flow-based graph neural network with biomedical network. Nat. Comput. Sci. 3, 1023–1033 (2023).
Article PubMed Google Scholar
-
Li, F. et al. DiffPROTACs is a deep learning-based generator for proteolysis targeting chimeras. Brief. Bioinform. 25, bbae358 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Alakhdar, A., Poczos, B. & Washburn, N. Diffusion models in de novo drug design. J. Chem. Inf. Model. 64, 7238–7256 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Wei, X. et al. Fragment-based discovery of small molecule inhibitors of the HDGFRP2 PWWP domain. FEBS Lett. 598, 2533–2543 (2024).
Article CAS PubMed Google Scholar
-
Wan, X. et al. An inductive graph neural network model for compound-protein interaction prediction based on a homogeneous graph. Brief. Bioinform. 23, bbac073 (2022).
-
Zhang, Z. et al. Graph neural network approaches for drug-target interactions. Curr. Opin. Struct. Biol. 73, 102327 (2022).
Article CAS PubMed Google Scholar
-
Han, K. et al. A review of approaches for predicting drug-drug interactions based on machine learning. Front. Pharmacol. 12, 814858 (2021).
Article PubMed Google Scholar
-
Wang, N. N. et al. Machine learning to predict metabolic drug interactions related to cytochrome P450 isozymes. J. Cheminform. 14, 23 (2022).
Article PubMed PubMed Central Google Scholar
-
Lin, X. et al. Comprehensive evaluation of deep and graph learning on drug-drug interactions prediction. Brief. Bioinform. 24, bbad235 (2023).
-
Nyamabo, A. K., Yu, H. & Shi, J. Y. SSI-DDI: substructure-substructure interactions for drug-drug interaction prediction. Brief. Bioinform. 22, bbab133 (2021).
-
Yan, X., Gu, C., Feng, Y. & Han, J. Predicting drug-drug interaction with graph mutual interaction attention mechanism. Methods 223, 16–25 (2024).
Article CAS PubMed Google Scholar
-
Dmitriev, A. V. et al. Drug-drug interaction prediction using PASS. SAR QSAR Environ. Res. 30, 655–664 (2019).
Article CAS PubMed Google Scholar
-
Yasir, M. et al. Machine learning-based drug repositioning of novel janus kinase 2 inhibitors utilizing molecular docking and molecular dynamic simulation. J. Chem. Inf. Model. 63, 6487–6500 (2023).
Article CAS PubMed Google Scholar
-
J, S. G., P, D. & P, E. Enhancing drug discovery in schizophrenia: a deep learning approach for accurate drug-target interaction prediction – DrugSchizoNet. Comput. Methods Biomech. Biomed. Engin. 28, 170–187 (2025).
-
Zhang, Y. et al. Neural network-based approaches for biomedical relation classification: a review. J. Biomed. Inform. 99, 103294 (2019).
Article PubMed Google Scholar
-
Shen, Z. A. et al. NPI-GNN: Predicting ncRNA-protein interactions with deep graph neural networks. Brief. Bioinform. 22, bbab051 (2021).
-
Zhao, Y. et al. Drug-drug interaction prediction: databases, web servers and computational models. Brief. Bioinform. 25, bbad445 (2023).
-
Kavuluru, R., Rios, A. & Tran, T. Extracting drug-drug interactions with word and character-level recurrent neural networks. Proc. IEEE Int. Conf. Health. Inf. 2017, 5–12 (2017).
Google Scholar
-
You, Y., Lu, C., Wang, W. & Tang, C. K. Relative CNN-RNN: learning relative atmospheric visibility from images. IEEE Trans. Image Process. 28, 45–55 (2019).
Article PubMed Google Scholar
-
Wang, J. & Guo, X. Automated detection of myocardial infarction based on an improved state refinement module for LSTM/GRU. Artif. Intell. Med. 152, 102865 (2024).
Article PubMed Google Scholar
-
Wang, J. et al. Visual analytics for RNN-based deep reinforcement learning. IEEE Trans. Vis. Comput. Graph 28, 4141–4155 (2022).
Article PubMed Google Scholar
-
Khaki, S., Wang, L. & Archontoulis, S. V. A CNN-RNN framework for crop yield prediction. Front. Plant Sci. 10, 1750 (2019).
Article PubMed Google Scholar
-
Zhang, Y. et al. A hybrid model based on neural networks for biomedical relation extraction. J. Biomed. Inform. 81, 83–92 (2018).
Article PubMed Google Scholar
-
Zaikis, D. & Vlahavas, I. TP-DDI: transformer-based pipeline for the extraction of Drug-Drug Interactions. Artif. Intell. Med. 119, 102153 (2021).
Article PubMed Google Scholar
-
Zaikis, D. & Vlahavas, I. TransformDDI: the transformer-based joint multi-task model for end-to-end drug-drug interaction extraction. IEEE J. Biomed. Health Inform. 29, 3045–3056 (2024).
Article Google Scholar
-
Järvinen, E. et al. 3D spheroid primary human hepatocytes for prediction of cytochrome P450 and drug transporter induction. Clin. Pharmacol. Ther. 113, 1284–1294 (2023).
Article PubMed Google Scholar
-
Colón Ortiz, R. et al. Cocaine regulates antiretroviral therapy CNS access through pregnane-x receptor-mediated drug transporter and metabolizing enzyme modulation at the blood brain barrier. Fluids Barriers CNS 21, 5 (2024).
Article PubMed PubMed Central Google Scholar
-
Cao, P. Y. et al. Group graph: a molecular graph representation with enhanced performance, efficiency and interpretability. J. Cheminform. 16, 133 (2024).
Article PubMed PubMed Central Google Scholar
-
Yin, H. et al. Inhibition of human UDP-glucuronosyltransferase enzyme by entrectinib: Implications for drug-drug interactions. Chem. Biol. Interact. 395, 111023 (2024).
Article CAS PubMed Google Scholar
-
Galetin, A., Burt, H., Gibbons, L. & Houston, J. B. Prediction of time-dependent CYP3A4 drug-drug interactions: impact of enzyme degradation, parallel elimination pathways, and intestinal inhibition. Drug Metab. Dispos. 34, 166–175 (2006).
Article CAS PubMed Google Scholar
-
Prieto Garcia, L. et al. Physiologically based pharmacokinetic model of itraconazole and two of its metabolites to improve the predictions and the mechanistic understanding of CYP3A4 drug-drug interactions. Drug Metab. Dispos. 46, 1420–1433 (2018).
Article PubMed Google Scholar
-
Han, H. et al. Employing automated machine learning (AutoML) methods to facilitate the in silico ADMET properties prediction. J. Chem. Inf. Model. 65, 3215–3225 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Menestrina, L. et al. Refined ADME profiles for ATC drug classes. Pharmaceutics. 17, 308 (2025).
-
Williams, D. P. et al. Predicting drug-induced liver injury with Bayesian machine learning. Chem. Res. Toxicol. 33, 239–248 (2020).
Article CAS PubMed Google Scholar
-
Semenova, E., Afzal, W. D. & Lazic, A. M. SE. A Bayesian neural network for toxicity prediction. Comput. Toxicol. 16, 100133 (2020).
Article Google Scholar
-
Smith, G. F. Artificial intelligence in drug safety and metabolism. Methods Mol. Biol. 2390, 483–501 (2022).
Article CAS PubMed Google Scholar
-
Mamoshina, P., Bueno-Orovio, A. & Rodriguez, B. Dual transcriptomic and molecular machine learning predicts all major clinical forms of drug cardiotoxicity. Front. Pharmacol. 11, 639 (2020).
Article PubMed PubMed Central Google Scholar
-
Hammann, F., Schöning, V. & Drewe, J. Prediction of clinically relevant drug-induced liver injury from structure using machine learning. J. Appl. Toxicol. 39, 412–419 (2019).
Article CAS PubMed Google Scholar
-
Joshi, P. V. M. & Mukherjee, A. A knowledge graph embedding based approach to predict the adverse drug reactions using a deep neural network. J. Biomed. Inform. 132, 104122 (2022).
Article PubMed Google Scholar
-
Rao, M. et al. Artificial intelligence and machine learning models for predicting drug-induced kidney injury in small molecules. Pharmaceuticals 17, 1550 (2024).
-
Liu, J. et al. In silico off-target profiling for enhanced drug safety assessment. Acta Pharm. Sin. B 14, 2927–2941 (2024).
Article PubMed PubMed Central Google Scholar
-
Kp Jayatunga, M. et al. How successful are AI-discovered drugs in clinical trials? A first analysis and emerging lessons. Drug Discov. Today 29, 104009 (2024).
Article CAS PubMed Google Scholar
-
Catacutan, D. B., Alexander, J., Arnold, A. & Stokes, J. M. Machine learning in preclinical drug discovery. Nat. Chem. Biol. 20, 960–973 (2024).
Article CAS PubMed Google Scholar
-
Cai, H. et al. FP-GNN: a versatile deep learning architecture for enhanced molecular property prediction. Brief. Bioinform. 23, bbac408 (2022).
Article PubMed Google Scholar
-
Ashe, E. C., Comeau, A. M., Zejdlik, K. & O’Connell, S. P. Characterization of bacterial community dynamics of the human mouth throughout decomposition via metagenomic, metatranscriptomic, and culturing techniques. Front. Microbiol. 12, 689493 (2021).
Article PubMed PubMed Central Google Scholar
-
Zhai, Y., Chen, L. & Deng, M. scGAD: a new task and end-to-end framework for generalized cell type annotation and discovery. Brief. Bioinform. 24, bbad045 (2023).
-
Wang, B. et al. STCGAN: a novel cycle-consistent generative adversarial network for spatial transcriptomics cellular deconvolution. Brief. Bioinform. 26, bbae670 (2024).
-
Mswahili, M. E. et al. Positional embeddings and zero-shot learning using BERT for molecular-property prediction. J. Cheminform. 17, 17 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Hao, M. et al. Large-scale foundation model on single-cell transcriptomics. Nat. Methods 21, 1481–1491 (2024).
Article CAS PubMed Google Scholar
-
Zhai, Y., Chen, L. & Deng, M. scBOL: a universal cell type identification framework for single-cell and spatial transcriptomics data. Brief. Bioinform. 25, bbae188 (2024).
-
Guo, Q., Yuan, M., Zhang, L. & Deng, M. scPLAN: a hierarchical computational framework for single transcriptomics data annotation, integration and cell-type label refinement. Brief. Bioinform. 25, bbae305 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Rozera, T., Pasolli, E., Segata, N. & Ianiro, G. Machine learning and artificial intelligence in the multi-omics approach to gut microbiota. Gastroenterology. 169, 487–501 (2025).
Article CAS PubMed Google Scholar
-
Dakal, T. C., Xu, C. & Kumar, A. Advanced computational tools, artificial intelligence and machine-learning approaches in gut microbiota and biomarker identification. Front. Med. Technol. 6, 1434799 (2024).
Article PubMed Google Scholar
-
Majidova, K. et al. Role of digital health and artificial intelligence in inflammatory bowel disease: a scoping review. Genes 12, 1465 (2021).
-
Zheng, J. et al. Noninvasive, microbiome-based diagnosis of inflammatory bowel disease. Nat. Med. 30, 3555–3567 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Huang, Q., Zhang, X. & Hu, Z. Application of artificial intelligence modeling technology based on multi-omics in noninvasive diagnosis of inflammatory bowel disease. J. Inflamm. Res. 14, 1933–1943 (2021).
Article PubMed PubMed Central Google Scholar
-
Xu, Z. et al. Precision medicine in colorectal cancer: leveraging multi-omics, spatial omics, and artificial intelligence. Clin. Chim. Acta 559, 119686 (2024).
Article CAS PubMed Google Scholar
-
Kann, B. H., Hosny, A. & Aerts, H. Artificial intelligence for clinical oncology. Cancer Cell 39, 916–927 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Tanaka, I., Furukawa, T. & Morise, M. The current issues and future perspective of artificial intelligence for developing new treatment strategy in non-small cell lung cancer: harmonization of molecular cancer biology and artificial intelligence. Cancer Cell Int. 21, 454 (2021).
Article PubMed PubMed Central Google Scholar
-
Barroso, R. A. et al. Unlocking antimicrobial peptides: in silico proteolysis and artificial intelligence-driven discovery from cnidarian omics. Molecules. 30, 550 (2025).
-
Feng, J. et al. A synthetic antibiotic class with a deeply-optimized design for overcoming bacterial resistance. Nat. Commun. 15, 6040 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Oh, H. S. et al. Organ aging signatures in the plasma proteome track health and disease. Nature 624, 164–172 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Duggan, M. R. & Walker, K. A. Organ-specific aging in the plasma proteome predicts disease. Trends Mol. Med. 30, 423–424 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Li, T. et al. Integrating machine learning and multi-omics analysis to reveal nucleotide metabolism-related immune genes and their functional validation in ischemic stroke. Front. Immunol. 16, 1561544 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Zhao, Y. et al. Integrating machine learning and single-cell transcriptomic analysis to identify potential biomarkers and analyze immune features of ischemic stroke. Sci. Rep. 14, 26069 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Hebron, M. et al. Discoidin domain receptor inhibition reduces neuropathology and attenuates inflammation in neurodegeneration models. J. Neuroimmunol. 311, 1–9 (2017).
Article CAS PubMed Google Scholar
-
Kortagere, S. et al. Identification of novel allosteric modulators of glutamate transporter EAAT2. ACS Chem. Neurosci. 9, 522–534 (2018).
Article CAS PubMed Google Scholar
-
Liu, B. et al. Retrosynthetic reaction prediction using neural sequence-to-sequence models. ACS Cent. Sci. 3, 1103–1113 (2017).
Article CAS PubMed PubMed Central Google Scholar
-
Wang, Y. et al. Retrosynthesis prediction with an interpretable deep-learning framework based on molecular assembly tasks. Nat. Commun. 14, 6155 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Hu, J., Luo, Y. & Wang, X. Multi-omics analysis of druggable genes to facilitate Alzheimer’s disease therapy: a multi-cohort machine learning study. J. Prev. Alzheimers Dis. 12, 100128 (2025).
Article PubMed PubMed Central Google Scholar
-
Cummings, J. et al. Alzheimer’s disease drug development pipeline: 2023. Alzheimers Dement. 9, e12385 (2023).
Google Scholar
-
Rodriguez, S. et al. Machine learning identifies candidates for drug repurposing in Alzheimer’s disease. Nat. Commun. 12, 1033 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Cheng, F. et al. Artificial intelligence and open science in discovery of disease-modifying medicines for Alzheimer’s disease. Cell Rep. Med. 5, 101379 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Zhou, Y. et al. AlzGPS: a genome-wide positioning systems platform to catalyze multi-omics for Alzheimer’s drug discovery. Alzheimers Res. Ther. 13, 24 (2021).
Article PubMed PubMed Central Google Scholar
-
Zulhafiz, N. A., Teoh, T. C., Chin, A. V. & Chang, S. W. Drug repurposing using artificial intelligence, molecular docking, and hybrid approaches: a comprehensive review in general diseases vs Alzheimer’s disease. Comput. Methods Prog. Biomed. 261, 108604 (2025).
Article Google Scholar
-
Wan, Z. et al. Applications of artificial intelligence in drug repurposing. Adv. Sci. 12, e2411325 (2025).
Article Google Scholar
-
Li, V. O. K. et al. DeepDrug as an expert guided and AI driven drug repurposing methodology for selecting the lead combination of drugs for Alzheimer’s disease. Sci. Rep. 15, 2093 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Shin, M. K. et al. Reducing acetylated tau is neuroprotective in brain injury. Cell 184, 2715–2732.e2723 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Min, S. W. et al. Critical role of acetylation in tau-mediated neurodegeneration and cognitive deficits. Nat. Med. 21, 1154–1162 (2015).
Article CAS PubMed PubMed Central Google Scholar
-
Fang, J. et al. Endophenotype-based in silico network medicine discovery combined with insurance record data mining identifies sildenafil as a candidate drug for Alzheimer’s disease. Nat. Aging 1, 1175–1188 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Paranjpe, M. D., Taubes, A. & Sirota, M. Insights into computational drug repurposing for neurodegenerative disease. Trends Pharmacol. Sci. 40, 565–576 (2019).
Article CAS PubMed PubMed Central Google Scholar
-
Sun, X. et al. Multi-omics Mendelian randomization integrating GWAS, eQTL and pQTL data revealed GSTM4 as a potential drug target for migraine. J. Headache Pain. 25, 117 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Bai, C. et al. Machine learning-enabled drug-induced toxicity prediction. Adv. Sci. 12, e2413405 (2025).
Article Google Scholar
-
Monzel, A. S. et al. Machine learning-assisted neurotoxicity prediction in human midbrain organoids. Parkinsonism Relat. Disord. 75, 105–109 (2020).
Article PubMed Google Scholar
-
Kuusisto, F. et al. Machine learning to predict developmental neurotoxicity with high-throughput data from 2D bio-engineered tissues. Proc. Int. Conf. Mach. Learn. Appl. 2019, 293–298 (2019).
PubMed Google Scholar
-
Zhao, X. et al. Machine learning modeling and insights into the structural characteristics of drug-induced neurotoxicity. J. Chem. Inf. Model. 62, 6035–6045 (2022).
Article CAS PubMed Google Scholar
-
Lee, B. et al. A deep learning approach with data augmentation to predict novel spider neurotoxic peptides. Int. J. Mol. Sci. 22, 12291 (2021).
-
Zeng, X. et al. Accurate prediction of molecular targets using a self-supervised image representation learning framework. Res. Sq. 3, 1477870 (2022).
Google Scholar
-
Parikh, J. et al. Generative adversarial networks for construction of virtual populations of mechanistic models: simulations to study Omecamtiv Mecarbil action. J. Pharmacokinet. Pharmacodyn. 49, 51–64 (2022).
Article PubMed Google Scholar
-
Cummings, J. Lessons learned from Alzheimer disease: clinical trials with negative outcomes. Clin. Transl. Sci. 11, 147–152 (2018).
Article PubMed Google Scholar
-
Shaker, B. et al. LightBBB: computational prediction model of blood-brain-barrier penetration based on LightGBM. Bioinformatics 37, 1135–1139 (2021).
Article CAS PubMed Google Scholar
-
Saxena, D., Sharma, A., Siddiqui, M. H. & Kumar, R. Blood brain barrier permeability prediction using machine learning techniques: an update. Curr. Pharm. Biotechnol. 20, 1163–1171 (2019).
Article CAS PubMed Google Scholar
-
Nada, H. et al. Machine learning-based approach to developing potent EGFR inhibitors for breast cancer-design, synthesis, and in vitro evaluation. ACS Omega 8, 31784–31800 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Bararia, A. et al. A multi-phase approach using supervised algorithms and clinical models to generate high-accuracy signatures for pancreatic cancer. Comput. Biol. Med. 194, 110559 (2025).
Article CAS PubMed Google Scholar
-
Sharma, S., Singh, R., Kant, S. & Mishra, M. K. Integrating AI/ML and multi-omics approaches to investigate the role of TNFRSF10A/TRAILR1 and its potential targets in pancreatic cancer. Comput. Biol. Med. 193, 110432 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Yan, H., Ji, X. & Li, B. Advancing personalized, predictive, and preventive medicine in bladder cancer: a multi-omics and machine learning approach for novel prognostic modeling, immune profiling, and therapeutic target discovery. Front. Immunol. 16, 1572034 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Cheerla, A. & Gevaert, O. Deep learning with multimodal representation for pancancer prognosis prediction. Bioinformatics 35, i446–i454 (2019).
Article CAS PubMed PubMed Central Google Scholar
-
Biswas, N. & Chakrabarti, S. Artificial intelligence (AI)-based systems biology approaches in multi-omics data analysis of cancer. Front. Oncol. 10, 588221 (2020).
Article PubMed PubMed Central Google Scholar
-
Chu, X. et al. Cancer stem cells: advances in knowledge and implications for cancer therapy. Signal Transduct. Target Ther. 9, 170 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
He, Z. et al. Multi-omics and tumor immune microenvironment characterization of a prognostic model based on aging-related genes in melanoma. Am. J. Cancer Res. 14, 1052–1070 (2024).
Article CAS PubMed Google Scholar
-
Abdelfattah, N. et al. Single-cell analysis of human glioma and immune cells identifies S100A4 as an immunotherapy target. Nat. Commun. 13, 767 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Mehrotra, S., Sharma, S. & Pandey, R. K. A journey from omics to clinicomics in solid cancers: success stories and challenges. Adv. Protein Chem. Struct. Biol. 139, 89–139 (2024).
Article CAS PubMed Google Scholar
-
Patkulkar, P. A., Subbalakshmi, A. R., Jolly, M. K. & Sinharay, S. Mapping spatiotemporal heterogeneity in tumor profiles by integrating high-throughput imaging and omics analysis. ACS Omega 8, 6126–6138 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Feng, Y. et al. Spatially organized tumor-stroma boundary determines the efficacy of immunotherapy in colorectal cancer patients. Nat. Commun. 15, 10259 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Cembrowska-Lech, D. et al. An integrated multi-omics and artificial intelligence framework for advance plant phenotyping in horticulture. Biology 12, 1298 (2023).
-
Imai, M. et al. Artificial intelligence-powered human epidermal growth factor receptor 2 and tumor microenvironment analysis in human epidermal growth factor receptor 2-amplified metastatic colorectal cancer: exploratory analysis of phase II TRIUMPH trial. JCO Precis. Oncol. 9, e2400385 (2025).
Article PubMed PubMed Central Google Scholar
-
Kumar, H. et al. secDrug: a pipeline to discover novel drug combinations to kill drug-resistant multiple myeloma cells using a greedy set cover algorithm and single-cell multi-omics. Blood Cancer J. 12, 39 (2022).
Article PubMed PubMed Central Google Scholar
-
Chen, W. et al. Integrating radiomics with genomics for non-small cell lung cancer survival analysis. J. Oncol. 2022, 5131170 (2022).
PubMed PubMed Central Google Scholar
-
Quek, C. et al. Single-cell spatial multiomics reveals tumor microenvironment vulnerabilities in cancer resistance to immunotherapy. Cell Rep. 43, 114392 (2024).
Article CAS PubMed Google Scholar
-
Hu, T. et al. Multi-omics and single-cell analysis reveals machine learning-based pyrimidine metabolism-related signature in the prognosis of patients with lung adenocarcinoma. Int. J. Med. Sci. 22, 1375–1392 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Kan, Z. et al. Real-world clinical multi-omics analyses reveal bifurcation of ER-independent and ER-dependent drug resistance to CDK4/6 inhibitors. Nat. Commun. 16, 932 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Au Yeung, V. P. W. et al. Computational approaches identify a transcriptomic fingerprint of drug-induced structural cardiotoxicity. Cell Biol. Toxicol. 40, 50 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Zhu, Z. et al. Two-dimensional deep learning frameworks for drug-induced cardiotoxicity detection. ACS Sens 9, 3316–3326 (2024).
Article CAS PubMed Google Scholar
-
Yu, L., Xu, Z., Qiu, W. & Xiao, X. MSDSE: predicting drug-side effects based on multi-scale features and deep multi-structure neural network. Comput. Biol. Med. 169, 107812 (2024).
Article CAS PubMed Google Scholar
-
Uner, O. C. et al. DeepSide: a deep learning approach for drug side effect prediction. IEEE/ACM Trans. Comput. Biol. Bioinform. 20, 330–339 (2023).
Article CAS PubMed Google Scholar
-
Wei, J. et al. GCFMCL: predicting miRNA-drug sensitivity using graph collaborative filtering and multi-view contrastive learning. Brief. Bioinform. 24, bbad247 (2023).
-
Mason, D. M. et al. Optimization of therapeutic antibodies by predicting antigen specificity from antibody sequence via deep learning. Nat. Biomed. Eng. 5, 600–612 (2021).
Article CAS PubMed Google Scholar
-
Sinha, S. et al. PERCEPTION predicts patient response and resistance to treatment using single-cell transcriptomics of their tumors. Nat. Cancer 5, 938–952 (2024).
Article PubMed Google Scholar
-
Joshi, A., Rienks, M., Theofilatos, K. & Mayr, M. Systems biology in cardiovascular disease: a multiomics approach. Nat. Rev. Cardiol. 18, 313–330 (2021).
Article PubMed Google Scholar
-
Kiessling, P. & Kuppe, C. Spatial multi-omics: novel tools to study the complexity of cardiovascular diseases. Genome Med. 16, 14 (2024).
Article PubMed PubMed Central Google Scholar
-
Xu, Y. et al. An atlas of genetic scores to predict multi-omic traits. Nature 616, 123–131 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Ouwerkerk, W. et al. Multiomics analysis provides novel pathways related to progression of heart failure. J. Am. Coll. Cardiol. 82, 1921–1931 (2023).
Article CAS PubMed Google Scholar
-
Yang, J. et al. Phenotypic screening with deep learning identifies HDAC6 inhibitors as cardioprotective in a BAG3 mouse model of dilated cardiomyopathy. Sci. Transl. Med. 14, eabl5654 (2022).
Article CAS PubMed Google Scholar
-
Theodoris, C. V. et al. Transfer learning enables predictions in network biology. Nature 618, 616–624 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Shi, H. & Zhang, S. Accurate prediction of anti-hypertensive peptides based on convolutional neural network and gated recurrent unit. Interdiscip. Sci. 14, 879–894 (2022).
Article CAS PubMed Google Scholar
-
Ma, C., Zhou, Z., Liu, H. & Koslicki, D. KGML-xDTD: a knowledge graph-based machine learning framework for drug treatment prediction and mechanism description. Gigascience 12, giad057 (2022).
-
Preuss, M. et al. Design of the coronary artery disease genome-wide replication and meta-analysis (CARDIoGRAM) study: a genome-wide association meta-analysis involving more than 22 000 cases and 60 000 controls. Circ. Cardiovasc. Genet. 3, 475–483 (2010).
Article CAS PubMed PubMed Central Google Scholar
-
Musunuru, K. et al. From noncoding variant to phenotype via SORT1 at the 1p13 cholesterol locus. Nature 466, 714–719 (2010).
Article CAS PubMed PubMed Central Google Scholar
-
Linsel-Nitschke, P. et al. Genetic variation at chromosome 1p13.3 affects sortilin mRNA expression, cellular LDL-uptake and serum LDL levels which translates to the risk of coronary artery disease. Atherosclerosis 208, 183–189 (2010).
Article CAS PubMed Google Scholar
-
Wang, Z., Gerstein, M. & Snyder, M. RNA-Seq: a revolutionary tool for transcriptomics. Nat. Rev. Genet. 10, 57–63 (2009).
Article CAS PubMed PubMed Central Google Scholar
-
Wu, P. Y. et al. Cardiovascular transcriptomics and epigenomics using next-generation sequencing: challenges, progress, and opportunities. Circ. Cardiovasc. Genet. 7, 701–710 (2014).
Article PubMed PubMed Central Google Scholar
-
Mohammadi, P. et al. Genetic regulatory variation in populations informs transcriptome analysis in rare disease. Science 366, 351–356 (2019).
Article CAS PubMed PubMed Central Google Scholar
-
Franzén, O. et al. Cardiometabolic risk loci share downstream cis- and trans-gene regulation across tissues and diseases. Science 353, 827–830 (2016).
Article PubMed PubMed Central Google Scholar
-
Human genomics The Genotype-Tissue Expression (GTEx) pilot analysis: multitissue gene regulation in humans. Science 348, 648–660 (2015).
Article Google Scholar
-
Khan, S. U. et al. PCSK9 inhibitors and ezetimibe with or without statin therapy for cardiovascular risk reduction: a systematic review and network meta-analysis. BMJ 377, e069116 (2022).
Article PubMed Google Scholar
-
Ren, Z. H. et al. DeepMPF: deep learning framework for predicting drug-target interactions based on multi-modal representation with meta-path semantic analysis. J. Transl. Med. 21, 48 (2023).
Article PubMed PubMed Central Google Scholar
-
Karlstädt, A. et al. CardioNet: a human metabolic network suited for the study of cardiomyocyte metabolism. BMC Syst. Biol. 6, 114 (2012).
Article PubMed PubMed Central Google Scholar
-
Edwards, L. M. et al. Genome-scale methods converge on key mitochondrial genes for the survival of human cardiomyocytes in hypoxia. Circ. Cardiovasc. Genet. 7, 407–415 (2014).
Article CAS PubMed Google Scholar
-
Zong, N. et al. Advancing efficacy prediction for EHR-based emulated trials in repurposing heart failure therapies. NPJ Digit. Med. 8, 306 (2025).
-
Wang, L. et al. Implementation of preemptive DNA sequence-based pharmacogenomics testing across a large academic medical center: the Mayo-Baylor RIGHT 10K Study. Genet. Med. 24, 1062–1072 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Tan, H. et al. Machine learning approach reveals microbiome, metabolome, and lipidome profiles in type 1 diabetes. J. Adv. Res. 64, 213–221 (2024).
Article CAS PubMed Google Scholar
-
Allesøe, R. L. et al. Author Correction: Discovery of drug-omics associations in type 2 diabetes with generative deep-learning models. Nat. Biotechnol. 41, 1026 (2023).
Article PubMed PubMed Central Google Scholar
-
Shapiro, M. R. et al. Leveraging artificial intelligence and machine learning to accelerate discovery of disease-modifying therapies in type 1 diabetes. Diabetologia 68, 477–494 (2025).
Article PubMed Google Scholar
-
Zhang, F. et al. Harnessing omics data for drug discovery and development in ovarian aging. Hum. Reprod. Update 31, 240–268 (2025).
Article PubMed Google Scholar
-
Jusoh, A. S. et al. How generative artificial intelligence can transform drug discovery? Eur. J. Med. Chem. 295, 117825 (2025).
Article CAS PubMed Google Scholar
-
Rabaan, A. A. et al. Omics approaches in drug development against leishmaniasis: current scenario and future prospects. Pathogens 12, 39 (2022).
-
Hay, M. et al. Clinical development success rates for investigational drugs. Nat. Biotechnol. 32, 40–51 (2014).
Article CAS PubMed Google Scholar
-
Harrer, S., Shah, P., Antony, B. & Hu, J. Artificial intelligence for clinical trial design. Trends Pharmacol. Sci. 40, 577–591 (2019).
Article CAS PubMed Google Scholar
-
Gligorijevic, J. et al. Optimizing clinical trials recruitment via deep learning. J. Am. Med. Inform. Assoc. 26, 1195–1202 (2019).
Article PubMed PubMed Central Google Scholar
-
Fogel, D. B. Factors associated with clinical trials that fail and opportunities for improving the likelihood of success: a review. Contemp. Clin. Trials Commun. 11, 156–164 (2018).
Article PubMed PubMed Central Google Scholar
-
Persidis, A. The benefits of drug repositioning. Drug Discov. World 12, 9–12 (2011).
-
Baldi Antognini, A., Novelli, M., Zagoraiou, M. & Vagheggini, A. Compound optimal allocations for survival clinical trials. Biom. J. 62, 1730–1746 (2020).
Article PubMed Google Scholar
-
Perni, S., Jimenez, R. & Jagsi, R. Optimizing informed consent in cancer clinical trials. Semin. Radiat. Oncol. 33, 349–357 (2023).
Article PubMed Google Scholar
-
Sarkar, C. et al. Artificial intelligence and machine learning technology driven modern drug discovery and development. Int. J. Mol. Sci. 24, 2026 (2023).
-
van der Lee, M. & Swen, J. J. Artificial intelligence in pharmacology research and practice. Clin. Transl. Sci. 16, 31–36 (2023).
Article PubMed Google Scholar
-
Wilczok, D. & Zhavoronkov, A. Progress, pitfalls, and impact of AI-driven clinical trials. Clin. Pharmacol. Ther. 117, 887–890 (2025).
Article PubMed Google Scholar
-
Aguado, B. A. et al. The future of sex and gender in research. Cell 187, 1354–1357 (2024).
Article CAS PubMed Google Scholar
-
Bewley, S., McCartney, M., Meads, C. & Rogers, A. Sex, gender, and medical data. BMJ 372, n735 (2021).
Article PubMed Google Scholar
-
Boland, M. R., Elhadad, N. & Pratt, W. Informatics for sex- and gender-related health: understanding the problems, developing new methods, and designing new solutions. J. Am. Med. Inform. Assoc. 29, 225–229 (2022).
Article PubMed PubMed Central Google Scholar
-
Park, Y. et al. Comparison of methods to reduce bias from clinical prediction models of postpartum depression. JAMA Netw. Open 4, e213909 (2021).
Article PubMed PubMed Central Google Scholar
-
Zhou, W. et al. Global biobank meta-analysis initiative: powering genetic discovery across human disease. Cell Genom. 2, 100192 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Jian, X. et al. Genome-wide association study of cognitive function in diverse Hispanics/Latinos: results from the Hispanic Community Health Study/Study of Latinos. Transl. Psychiatry 10, 245 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Migliozzi, S. et al. Integrative multi-omics networks identify PKCδ and DNA-PK as master kinases of glioblastoma subtypes and guide targeted cancer therapy. Nat. Cancer 4, 181–202 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Bravo González-Blas, C. et al. Single-cell spatial multi-omics and deep learning dissect enhancer-driven gene regulatory networks in liver zonation. Nat. Cell Biol. 26, 153–167 (2024).
Article PubMed PubMed Central Google Scholar
-
Fatima, I. et al. Breakthroughs in AI and multi-omics for cancer drug discovery: a review. Eur. J. Med. Chem. 280, 116925 (2024).
Article CAS PubMed Google Scholar
-
Wen, Z. et al. Genetic insights into idiopathic pulmonary fibrosis: a multi-omics approach to identify potential therapeutic targets. J. Transl. Med. 23, 337 (2025).
Article CAS PubMed PubMed Central Google Scholar
-
Gao, R. et al. Secreted MUP1 that reduced under ER stress attenuates ER stress induced insulin resistance through suppressing protein synthesis in hepatocytes. Pharmacol. Res. 187, 106585 (2023).
Article CAS PubMed Google Scholar
-
Wang, T. et al. Identification of serum biomarkers and therapeutic targets for aortic diseases in obesity through multi-omics analysis. J. Thorac. Dis. 16, 8435–8449 (2024).
Article PubMed PubMed Central Google Scholar
-
Chen, Y. X. et al. An integrative multi-omics network-based approach identifies key regulators for breast cancer. Comput. Struct. Biotechnol. J. 18, 2826–2835 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Kim, N. et al. CCR8 as a therapeutic novel target: omics-integrated comprehensive analysis for systematically prioritizing indications. Biomedicines 11, 2910 (2023).
-
Vos, W. et al. The 2000HIV study: design, multi-omics methods and participant characteristics. Front. Immunol. 13, 982746 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Yang, B. et al. NetSDR: Drug repurposing for cancers based on subtype-specific network modularization and perturbation analysis. Biochim. Biophys. Acta Mol. Basis Dis. 1871, 167688 (2025).
Article CAS PubMed Google Scholar
-
Zillich, E. et al. Multi-omics profiling of DNA methylation and gene expression alterations in human cocaine use disorder. Transl. Psychiatry 14, 428 (2024).
Article CAS PubMed PubMed Central Google Scholar
-
Karaosmanoglu, K., Sayar, N. A., Kurnaz, I. A. & Akbulut, B. S. Assessment of berberine as a multi-target antimicrobial: a multi-omics study for drug discovery and repositioning. OMICS 18, 42–53 (2014).
Article CAS PubMed Google Scholar
-
Krumm, J. et al. High-throughput screening and proteomic characterization of compounds targeting myeloid-derived suppressor cells. Mol. Cell Proteom. 22, 100632 (2023).
Article CAS Google Scholar
-
Hell, T. et al. Combining activity profiling with advanced annotation to accelerate the discovery of natural products targeting oncogenic signaling in melanoma. J. Nat. Prod. 85, 1540–1554 (2022).
Article CAS PubMed Google Scholar
-
Ory, L. et al. Targeting bioactive compounds in natural extracts—development of a comprehensive workflow combining chemical and biological data. Anal. Chim. Acta 1070, 29–42 (2019).
Article CAS PubMed Google Scholar
-
Zhu, J. et al. SSF-DDI: a deep learning method utilizing drug sequence and substructure features for drug-drug interaction prediction. BMC Bioinforma. 25, 39 (2024).
Article Google Scholar
-
Wang, Z. & Wei, Z. A framework for pre-training biomedical knowledge graphs with graph neural networks. Comput. Biol. Med. 178, 108768 (2024).
Article PubMed Google Scholar
-
He, C. et al. Multi-type feature fusion based on graph neural network for drug-drug interaction prediction. BMC Bioinforma. 23, 224 (2022).
Article Google Scholar
-
Zhang, Y. et al. Predicting drug-drug interactions using multi-modal deep auto-encoders based network embedding and positive-unlabeled learning. Methods 179, 37–46 (2020).
Article CAS PubMed Google Scholar
-
Ren, Z. H. et al. BioChemDDI: predicting drug-drug interactions by fusing biochemical and structural information through a self-attention mechanism. Biology 11, 758 (2022).
-
Zang, X., Zhao, X. & Tang, B. Hierarchical molecular graph self-supervised learning for property prediction. Commun. Chem. 6, 34 (2023).
Article PubMed PubMed Central Google Scholar
-
Wang, Z. et al. DEML: drug synergy and interaction prediction using ensemble-based multi-task learning. Molecules 28, 844 (2023).
-
Coaviche-Yoval, A. et al. In silico and in vivo neuropharmacological evaluation of two γ-amino acid isomers derived from 2,3-disubstituted benzofurans, as ligands of GluN1-GluN2A NMDA receptor. Amino Acids 54, 215–228 (2022).
Article CAS PubMed Google Scholar
-
Tang, Y. et al. Structure-based discovery of CZL80, a caspase-1 inhibitor with therapeutic potential for febrile seizures and later enhanced epileptogenic susceptibility. Br. J. Pharmacol. 177, 3519–3534 (2020).
Article CAS PubMed PubMed Central Google Scholar
-
Qiang, S. J. et al. The discovery of novel PGK1 activators as apoptotic inhibiting and neuroprotective agents. Front. Pharmacol. 13, 877706 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Pandey, P. et al. Structure-based identification of potent natural product chemotypes as cannabinoid receptor 1 inverse agonists. Molecules 23, 2630 (2018).
-
Ozhathil, L. C. et al. Identification of potent and selective small molecule inhibitors of the cation channel TRPM4. Br. J. Pharmacol. 175, 2504–2519 (2018).
Article CAS PubMed PubMed Central Google Scholar
-
Kampen, S. et al. Structure-based discovery of negative allosteric modulators of the metabotropic glutamate receptor 5. ACS Chem. Biol. 17, 2744–2752 (2022).
Article CAS PubMed PubMed Central Google Scholar
-
Zhou, J. et al. Machine-learning-enabled virtual screening for inhibitors of lysine-specific histone demethylase 1. Molecules 26, 7492 (2021).
-
Wei, L. et al. Hit identification driven by combining artificial intelligence and computational chemistry methods: a PI5P4K-β case study. J. Chem. Inf. Model. 63, 5341–5355 (2023).
Article CAS PubMed Google Scholar
-
Reker, D., Schneider, P. & Schneider, G. Multi-objective active machine learning rapidly improves structure-activity models and reveals new protein-protein interaction inhibitors. Chem. Sci. 7, 3919–3927 (2016).
Article CAS PubMed PubMed Central Google Scholar
-
Boniolo, F. et al. Artificial intelligence in early drug discovery enabling precision medicine. Expert Opin. Drug Discov. 16, 991–1007 (2021).
Article CAS PubMed Google Scholar
-
Limeta, A. et al. Leveraging high-resolution omics data for predicting responses and adverse events to immune checkpoint inhibitors. Comput. Struct. Biotechnol. J. 21, 3912–3919 (2023).
Article CAS PubMed PubMed Central Google Scholar
-
Fountzilas, E., Tsimberidou, A. M., Vo, H. H. & Kurzrock, R. Clinical trial design in the era of precision medicine. Genome Med. 14, 101 (2022).
Article PubMed PubMed Central Google Scholar
-
Moingeon, P., Kuenemann, M. & Guedj, M. Artificial intelligence-enhanced drug design and development: toward a computational precision medicine. Drug Discov. Today 27, 215–222 (2022).
Article CAS PubMed Google Scholar
-
Ahmed, Z. Precision medicine with multi-omics strategies, deep phenotyping, and predictive analysis. Prog. Mol. Biol. Transl. Sci. 190, 101–125 (2022).
Article CAS PubMed Google Scholar
-
Kolla, L. et al. The case for AI-driven cancer clinical trials—the efficacy arm in silico. Biochim Biophys. Acta Rev. Cancer 1876, 188572 (2021).
Article CAS PubMed PubMed Central Google Scholar
-
Hartl, D. et al. Translational precision medicine: an industry perspective. J. Transl. Med. 19, 245 (2021).
Article PubMed PubMed Central Google Scholar
-
Sedano, R. et al. Artificial intelligence to revolutionize IBD clinical trials: a comprehensive review. Ther. Adv. Gastroenterol. 18, 17562848251321915 (2025).
Article PubMed PubMed Central Google Scholar
-
Wei, L. et al. Artificial intelligence (AI) and machine learning (ML) in precision oncology: a review on enhancing discoverability through multiomics integration. Br. J. Radiol. 96, 20230211 (2023).
Article PubMed PubMed Central Google Scholar
-
Terranova, N. & Venkatakrishnan, K. Machine learning in modeling disease trajectory and treatment outcomes: an emerging enabler for model-informed precision medicine. Clin. Pharmacol. Ther. 115, 720–726 (2024).
Article PubMed Google Scholar
-
Lorkowski, J., Kolaszyńska, O. & Pokorski, M. Artificial intelligence and precision medicine: a perspective. Adv. Exp. Med. Biol. 1375, 1–11 (2022).
PubMed Google Scholar
Download references
Acknowledgements
This work was financially supported by the National Natural Science Foundation of China (Nos. 82274027, 82474014, and 82374552), the Hunan Provincial Natural Science Foundation for Distinguished Young Scholars (No. 2024JJ2086), the Hunan Provincial Natural Science Foundation for Distinguished Young Scholars (No. 2025JJ20087), and the Science and Technology Innovation Program of Hunan Province (No. 2022RC1220).
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
Reprints and permissions
About this article

Cite this article
Liu, Y., Zhu, K., Peng, W. et al. Multi-omics and artificial intelligence for precision drug discovery and potential clinical applications. Sig Transduct Target Ther 11, 210 (2026). https://doi.org/10.1038/s41392-026-02631-6
Download citation
-
Received:
-
Revised:
-
Accepted:
-
Published:
-
Version of record:
-
DOI: https://doi.org/10.1038/s41392-026-02631-6
Related Posts